최근 읽은 논문/아티클 정리 (Triplet Loss for Knowledge Distillation, Weight Distillation, Understanding and Improving Knowledge Distillation)
논문 세편 (Triplet Loss for Knowledge Distillation, Weight Distillation, Understanding and Improving Knowledge Distillation)을 읽고 정리했다.
Triplet Loss for Knowledge Distillation
- IJCNN 2020
- Metric Learning에서의 KD라 보면 된다.
- Triplet Loss를 anchor에 대해서 positive를 가까이 만들고 negative를 멀게 만드는데, 이 논문에서는 knowledge distillation과 같이 수행하기 위해 조금 변경했다.
- 아래처럼 바꿈
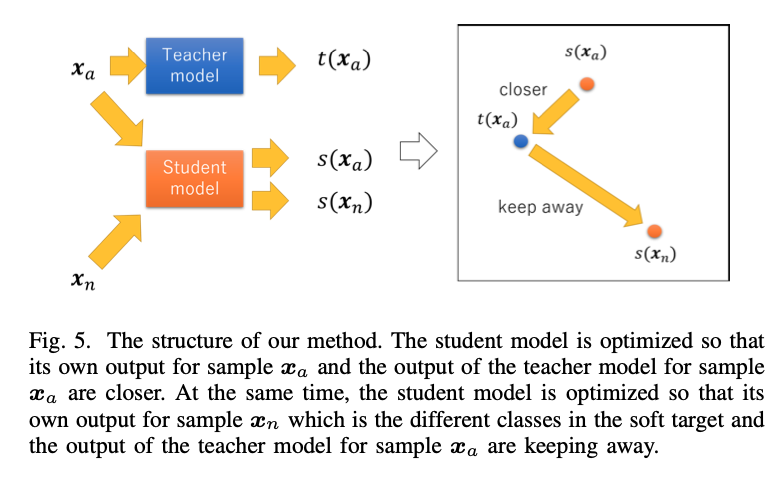
- 실제로 teacher의 embedding space를 따서 student를 만들어야 하는 경우 꽤 좋은 방법인 것 같아서 아이디어만 정리
Weight Distillation: Transferring the Knowledge in Neural Network Parameters
- 아래의 개념이 너무 신기해서 정리
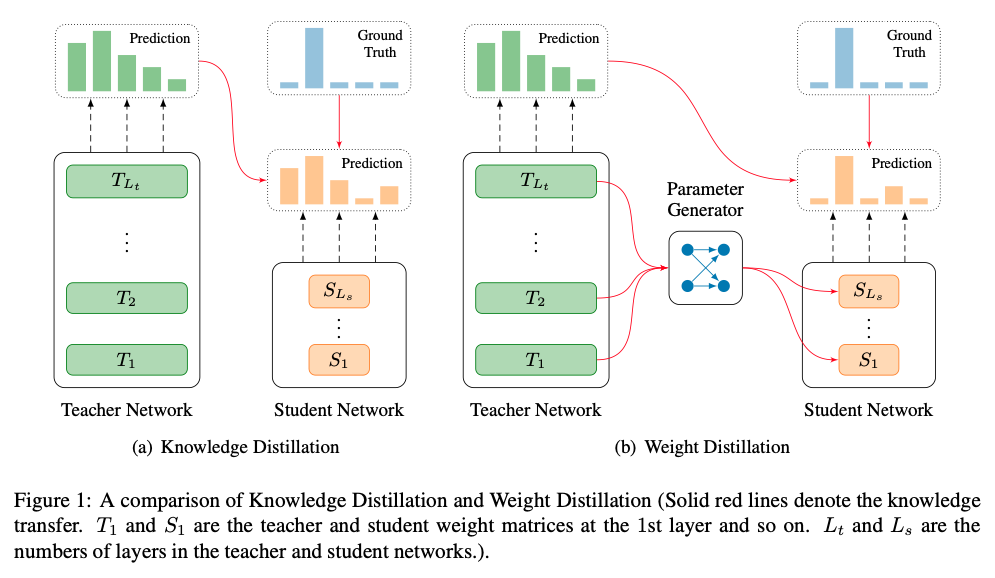
- teacher의 soft label에 대해 학습을 하는 것이 아니라 parameter generator를 학습함
- 학습은 페이즈가 2개인데,
- 먼저 parameter generator를 학습한다.
- 그리고 그를 통해 얻은 student를 학습한다.
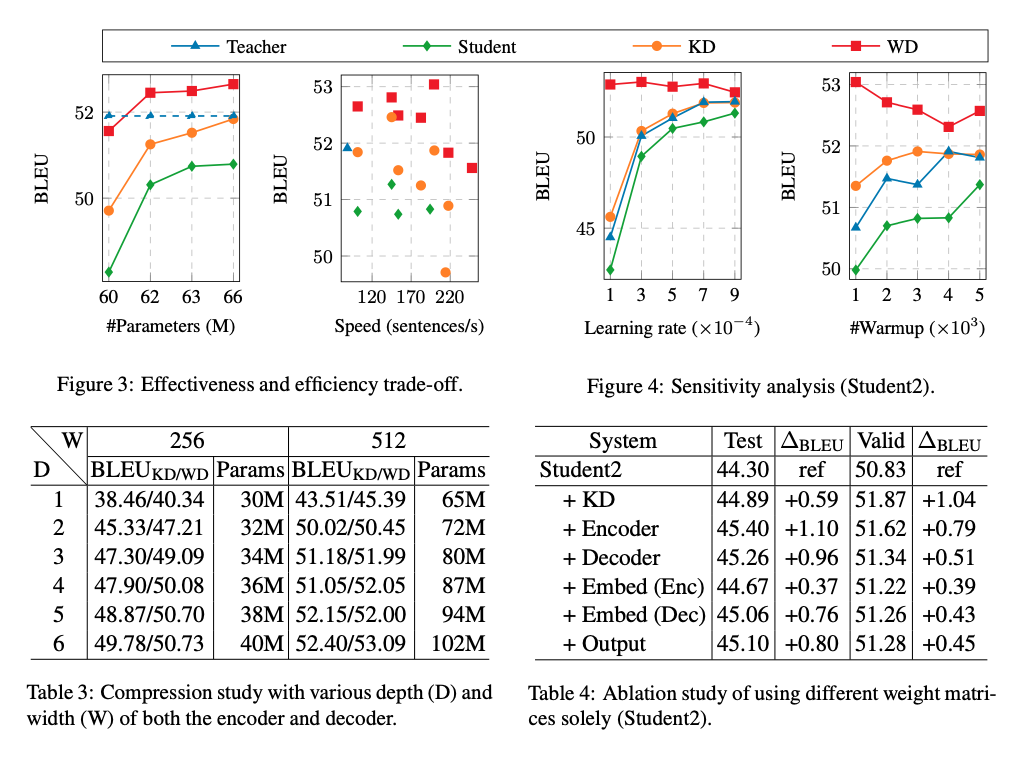
- 결과를 보면 꽤 괜찮다. KD에 비해 좀 더 robust하고, 성능이 덜 떨어진다.
- NMT에 대해서 성능을 테스트했지만, transfer learning의 관점에서 본다면 좋은 시도 같은데 한번 테스트해볼까..?
Understanding and Improving Knowledge Distillation
- KD를 아래의 관점에서 분석해봄
- Label Smoothing
- Example Re-weighting based on teacher’s condifence
- prior knowledge of optimal output layer geometry
- introduction
- 최근 연구에서 밝히길 꼭 teacher가 좋은 것이 좋은 student model을 만들지는 않는다고 한다. (Mirzadeh et al., 2019, Muller et al., 2019)
- 또한 좋은 teacher를 쓰지 않아도 mutual/self-distilation을 수행하면 student를 좋게 만들 수 있다고 한다.
- analysis
- label smoothing은 over-confidence issue를 방지할 수 있는 좋은 기법 중 하나. 그리고 model calibration을 잘 해준다.
- Knowledge Distillation을 그 관점에서 보면 adaptive version of label smoothing으로 볼 수 있다.
- teacher의 prediction confidence가 example re-weighting을 하는 것에 도움을 준다. -> 낮은 확률로 예측하는 것은 낮은 loss를 줄 수밖에 없고, 높은 확률로 예측하는 것은 큰 loss를 주므로, 그 자체로 도움이 된다.
- multiclass 분류에서 KD는 label간의 연관성을 쉽게 배울 수 있도록 도와준다.
- Partial Knowledge Distillation
- teacher logit을 활용해 label smoothing을 해봄 -> KD-pt
- class relationship을 학습할 수 있도록 \(\rho^{sim} = \text{softmax}(\hat w_t \hat {W^T})\)을 distillation 해봄 -> KD-sim
- \(W\)는 마지막 classification layer weight, \(w_t\)는 해당되는 row
- teacher logit에서 topk를 추려서 해당되는 logit만 distillation 해봄 -> KD-topk
- 다른 방법들은 기존 KD를 넘지 못함. 하지만 KD-topk는 language modeling과 image classification에서 기존 KD를 이김

- 추가] LS
- teacher model을 학습할 때 Label Smoothing은 teacher에 한해서만 더 좋은 결과를 가져온다.
- Label Smoothing은 class relationship을 그렇게 좋게 만들지 못한다.
- 추가] teacher model size
- Teacher model size가 너무 크면 Example에 대해 거의 높은 확률로 맞추므로, teacher 모델이 계속 커지면 student 모델의 성능이 안좋아진다. -> example re-weighting을 없앤다.
- 아니면 teacher에게 쉬운 내용이 student에게 너무 어려울 수도 있다는 설명도 가능한 것으로 보인다.
- BERT-PKD에서도 이런 내용에 대해 다루었었다. BERT-12layer가 BERT-24layer보다 잘 가르칠 때가 많다.
October 21, 2020
Tags:
paper