DistilBert 리뷰
오늘은 huggingface가 huggingface/transformers 레포지토리에 자체적으로 공개한 모델인 DistilBert를 읽고 정리해본다. 다른 정리처럼 한번 읽고 말 부분은 다 제외한다.
원 논문은 DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter로 가면 읽을 수 있다.
Abstract
최근 더욱 잘 학습을 하기 위해서 pretrain -> fine tuning으로 가는 방법이 많아지고 흔해졌지만, 모델 자체가 너무 크기 때문에 제한된 환경에서는 굉장히 사용하기 힘들다. 그래서 huggingface에서 DistilBert라는 general purpose language representation model을 만들어보았다고 한다. BERT를 40% 정도 줄이고 60%나 빠르게 연산하면서 97%의 성능을 유지했다고 한다.
1. Introduction
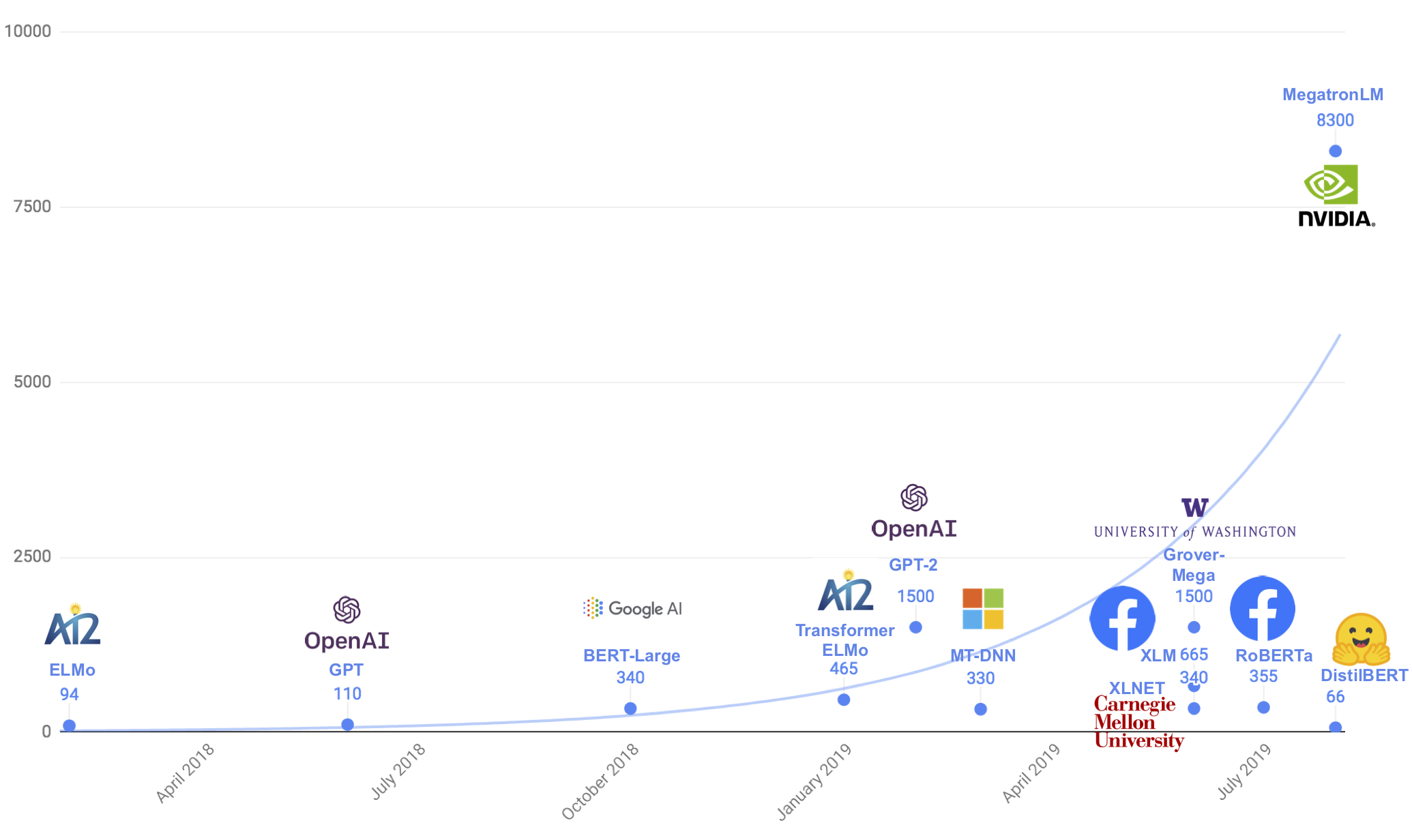
이렇게 큰 모델들이 많이 나오고 있는데, Schwartz et al. [2019], Strubell et al. [2019]에서 언급한 것처럼 해당 모델을 연산하기 위한 컴퓨팅 파워가 급격히 증가하고 있다. 그리고 NLP 특성 상 on-device나 real-time에서 활용할 가치가 많을텐데 이런 추세가 활용할 수 있는 길을 막는 것 같다고 한다.
2. Knowledge distillation
Knowledge Distillation [Bucila et al., 2006, Hinton et al., 2015]은 larger model(teacher model)로부터 compact model(student model)을 만들어내는 방법이다. 이게 작은 모델을 바로 학습시키는 것보다 의미있는 이유는 near-zero인 확률들도 학습할 수 있기 때문이다. 고양이 사진을 분류한다고 할 때 차와 호랑이에 대한 확률이 0에 가깝겠지만, 호랑이에 대한 확률이 더 클 것이고, 그런 정보도 학습이 되기 때문에 의미가 있다.
student를 학습하기 위해서 teacher의 output을 그대로 이용한다. teacher의 output의 모델의 output이기 때문에 soft target prob인데, 이 prob을 비교하는 loss가 distillation loss이다. (\(L_{ce} = \sum_i t_i * \log(s_i)\), \(t_i\)가 teacher model의 soft target prob) 이 \(L_{ce}\)와 함께 Hinton et al. [2015]를 따라 softmax-temperature \(p_i = \frac {\exp{(z_i / T)}} {\sum_j \exp{(z_j / T)}}\) 를 사용한다. \(T\)가 output distribution의 smoothness를 결정한다. training 동안에만 \(T\)를 조정하고 inference 시간에는 1로 설정해서 standard softmax로 사용한다.
final training loss는 distillation loss \(L_{ce}\)와 BERT에서 사용한 \(L_{mlm}\)의 linear combination이라고 한다.
3. DistilBERT: a distilled version of BERT
student layer의 구조는 BERT랑 똑같은데 token type embedding이랑 pooler layer는 없어졌고, transformer block을 두배로 줄였다. 그리고 initialization은 teacher의 레이어 두개당 하나를 취했다.
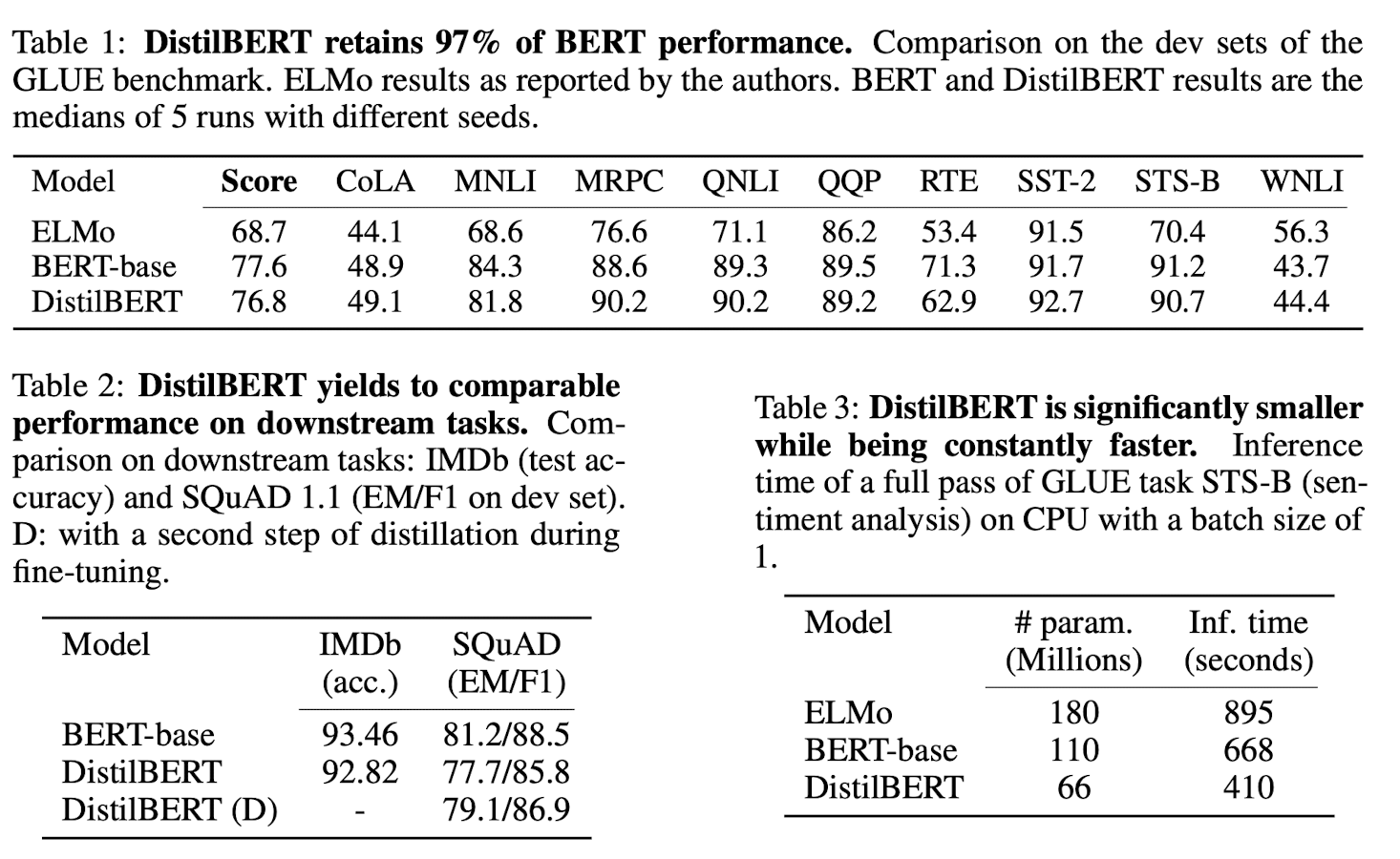
기타
ablation study에서 Masked LM loss를 없애는 것은 생각보다 성능에 큰 영향이 없었다고.
그리고 distillation에 대한 다른 시도들도 찾아보는 것이 좋을 것 같다. 예를 들어 BERT를 LSTM으로 distillation으로 진행한 Tang et al. [2019]이나, SQuAD에 이미 fine-tuning된 것을 distillate한 Chatterjee [2019]등이 좋을 것 같다. 그리고 multitask model을 distillate한 Yang et al. [2019]도 읽기에 좋을 것 같다.
읽어보고 싶은 것들
- Knowledge Distillation [Bucila et al., 2006, Hinton et al., 2015]
- Hinton et al. [2015]
- Chatterjee [2019]
- Tang et al. [2019]
- Yang et al. [2019]