ALBERT 리뷰
최근 회사에서의 업무 때문에 논문을 많이 찾아보게 되었는데, 그리 되어서 어쨌든 ALBERT도 읽었으니 정리. 귀찮은 부분은 건너뛴다. 논문은 ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS이다. Google Research랑 Toyota Technological Institute at Chicago에서 했다.
Abstract
- 메모리 덜 먹고 더 빠른 BERT를 위해 parameter reduction technique를 두가지 보여준다고 한다.
- inter-sentence coherence를 modeling 하기 위한 self-supervised learning loss를 사용한다.
- 그리고 그게 multi-sentence input을 넣는 downstream task에 도움이 된다는 것도 보여준다.
- 결과적으로 BERT large보다 적은 파라미터로 더 좋은 결과를 내는 모델을 보여준다.
코드는 google-research/google-research/tree/master/albert서 확인할 수 있다.
1 Introduction
좋은 성능에는 large model이 필요하다. 그래서 large model을 pretrain하고 나서 real application을 위해 작은 모델로 distillate한다. 근데 이게 larger 모델 바로 학습 안하고 그냥 작은 모델 학습하면 안되나?가 이 연구팀이 제기한 의문의 핵심이라고.
그래서 존재하는 해결책을 찾아보니까 model parallelization(Shoeybi et al., 2019)과 clever memory management(Chen et al., 2016; Gomez et al., 2017)인데, memory limiation problem을 해결하지만, communication overhead와 mdel degradation problem을 해결하지 못한다. 그래서 이 논문에서는 A Lite BERT(ALBERT) 를 디자인 했다고 한다.
ALBERT는 두가지 parameter reduction technique을 보여준다. 첫 번째는 embedding parameter를 factorize하는 것이고 두번째는 cross layer parameter sharing이다. 그리고 또 ALBERT의 성능을 위해서 sentence-order prediction(SOP)이라는 self-supervised loss를 새로 만들었다고 한다.
결과적으로 BERT large보다 좋은 성능을 보이지만, 파라미터는 엄청 적은 ALBERT를 만들 수 있었다.
2 RELATED WORK
나중에 그냥 직접 읽자.
3 THE ELEMENTS OF ALBERT
MODEL ARCHITECTURE CHOICES
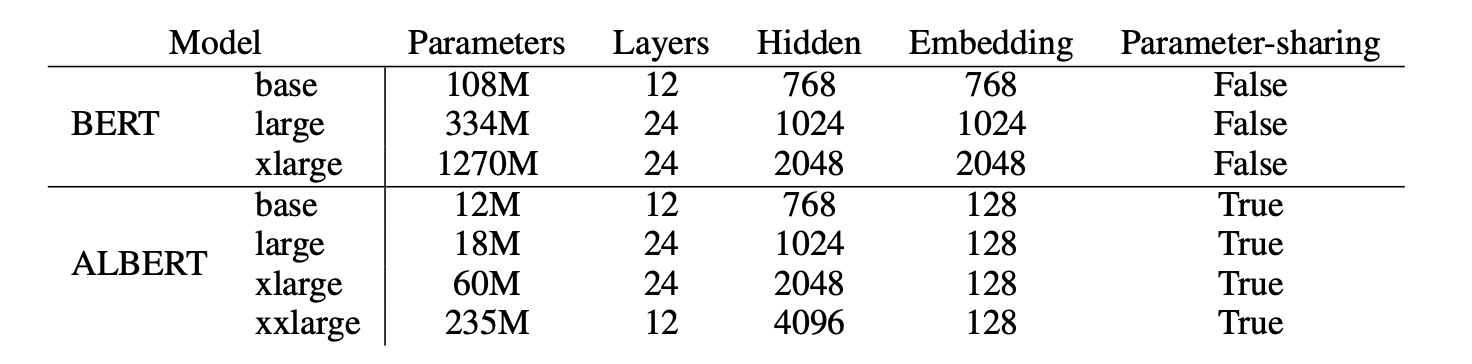
ALBERT는 BERT랑 엄청 유사한데, gelu 사용하는 transformer encoder도 그대로 쓴다. embedding size는 E, encoder layer 개수는 L, hidden size는 H로 사용하고 feed-forward/filter size를 4H로 쓰고, attention heads도 H/64로 사용한다.
Factorized embedding parameterization.
BERT에서는 WordPiece Embedding size E와 hidden layer size H를 똑같이 했는데, 이런 결정은 좀 별로다.
modeling 관점에서 보면 WordPiece embedding은 context-independent representation을 배우고, hidden layer embedding은 context-dependent representation을 배우는 것인데, 굳이 똑같이 size를 맞출 이유가 있나?라는 것이다. size를 다르게 하면 효과적으로 model parameter를 더 줄이면서 학습을 그대로 진행할 수 있다. H가 물론 더 크다.
practical 관점에서 보면 Natural Language는 vocab size V가 엄청 큰데, H랑 E랑 사이즈를 맞추어버리면 vocab embedding size(V X E)가 엄청 커진다. 그래서 hidden space로 projection하는 레이어(E X H)를 하나 더 만들어주는 것이 더 파라미터 개수를 많이 줄일 수 있다. 그래서 이렇게 해서 파라미터 숫자를 O(V × H)에서 O(V × E + E × H)로 줄였다. E가 H보다 엄청 작다.
Cross-layer parameter sharing
ALBERT에서는 layer의 모든 파라미터를 공유한다. 즉, BERT가 transformer block 1~12까지 거쳤으면 ALBERT에서는 transformer block 1을 12번 거친다.
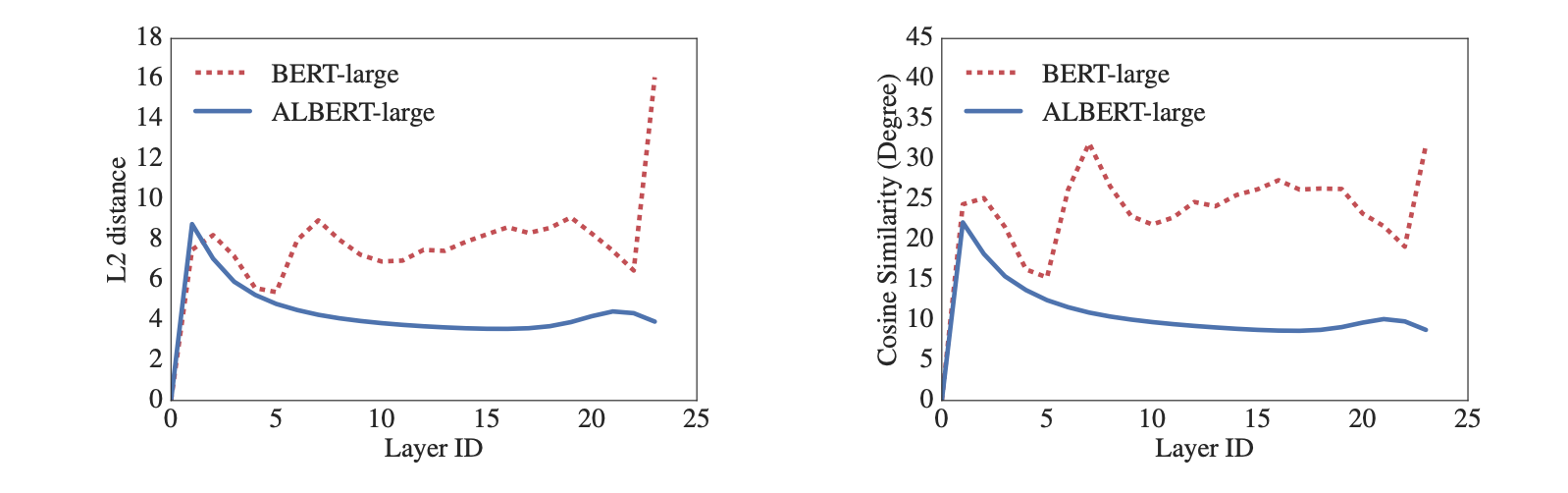
그 결과 각 레이어의 input, output embedding의 L2 distance랑 cosine similarity가 이렇게 부드러워졌다고. 난 이게 무슨 의미인지 잘 몰랐는데, ML 엔지니어분께 여쭈어 보니까 정답이라고 할 수는 없지만, “한 레이어에서 수행하는 역할이 적어지고 그에 따라 더 모델을 안정적으로 학습하기 쉽다는 의미가 될 수 있다. 또 BERT는 한 레이어에서 input, output을 확확 바꾸니 레이어를 많이 쌓는다는게 정말 좋기만 한 것인가?인데, ALBERT는 정말 안정적인 결과를 기대할 수 있다는 의미로도 보인다.”라고 답해주셨다.
Inter-sentence coherence loss.
NSP는 downstream task의 성능을 높이기 위해 만들어졌지만, (Yang et al., 2019; Liu et al., 2019)와 같은 연구들에서 NSP의 영향이 그렇게 막 좋지도 않고 없앴다고 한다. 그래서 inter-sentence coherence를 학습할 수있는 다른 방법을 고안했는데, 그게 SOP이다.
SOP에서 NSP에다가 하나를 더 얹었는데, 연속된 문장이지만 순서가 바뀐 sequence인 것들을 넣어주었다고 한다. 그래서 결과를 보니까 NSP로 학습시킨 모델은 SOP을 전혀 못푸는데, SOP으로 학습시킨 모델은 NSP를 잘 푼다고 한다.
MODEL SETUP
4 EXPERIMENTAL RESULTS
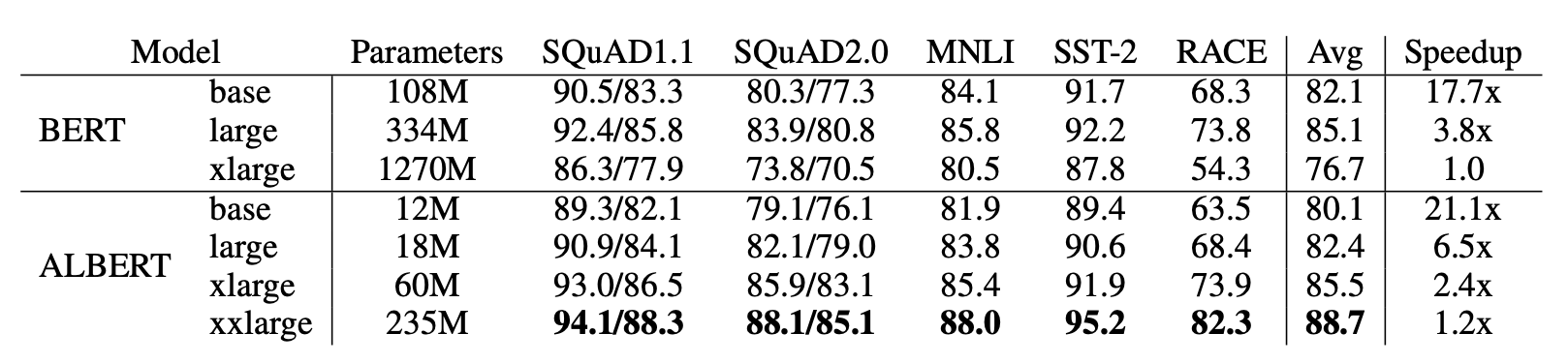
OVERALL COMPARISON BETWEEN BERT AND ALBERT
CROSS-LAYER PARAMETER SHARING
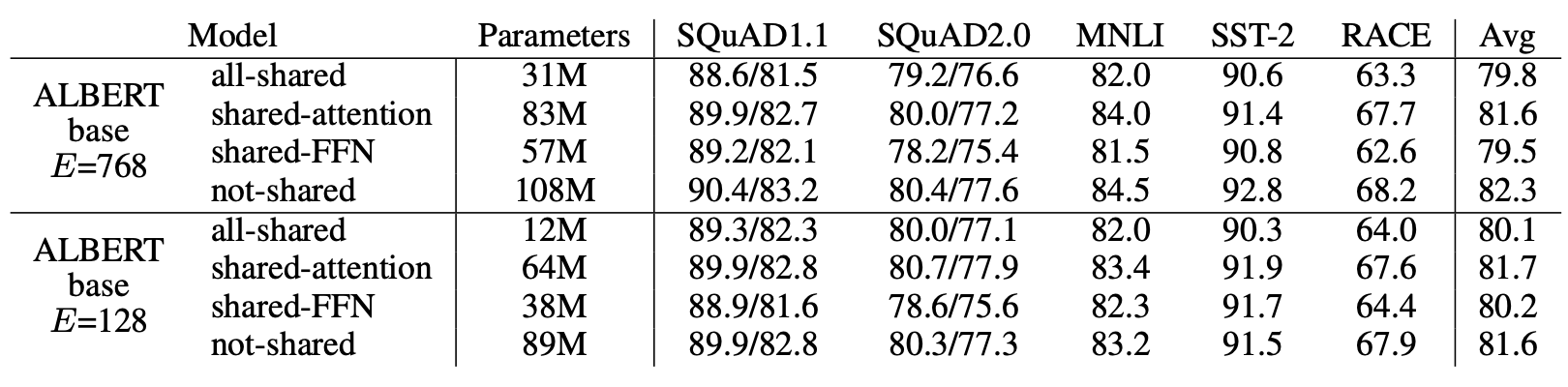
전체 sharing하는 것이 성능하락이 있긴 있다.
SENTENCE ORDER PREDICTION (SOP)

None이 XLNet, RoBERTa 스타일이다.
그 외에도 결과에 재밌는 게 많은데, “더 쌓아도 의미가 있나?”, “BERT랑 똑같은 시간동안 학습시켜보기”, “H 변화시키기” 등등, 읽어보면 재밌다.