transformers.zip 리뷰
transformers.zip: Compressing Transformers with Pruning and Quantization이라는 논문인데, url을 보니까 cs224n reports인 듯 싶다.. https://github.com/robeld/ERNIE로 가면 소스코드를 확인할 수 있다.
Abstract
Transformer architecture에 compression tenchnique을 여러가지 적용했다. quantization 방법을 Song Han et al., 2015에서 언급한 k-means apporach랑 Maximilian Lam, 2018의 수정된 버전인 binarization을 적용해보았다고 한다. 그리고 iterative magnitude pruning도 해보았다고.
Introduction
quantization은 performance 손실없이 엄청나게 압축할 수 있는 것으로 보인다. (float32를 float16으로만 고쳐도 절반이니까..) Song Han et al., 2015에서 5% 안쪽으로만 손실을 보면서 computation resource랑 memory costs를 엄청 줄이는 방법을 보여줬다.
그래서 결론적으로 이 논문에서는 이렇게 한다.
- k-means algorithm을 구현해서 4 bit representation으로 만들어서 5.85x 압축을 하고도 원래 성능의 98.43% 성능을 보여준다.
- binarization algorithm을 구현해서 얼마나 빠르고, 얼마나 성능 손실이 있는지 비교해본다.
- iterative magnitude pruning을 구현해본다.
- self-attention을 visualizing하는 것에 초점을 맞추어본다. 특히, compression이 진행될 수록 model이 sharper representation을 뽑아내는 것을 보여준다.
Related Works
근데 여기서 소개하는 방법, 알고리즘 등등이 거의 다 원 논문을 일거야 이해갈 것 같아서 나중에 쭉 읽으면서 다 이해해야할 듯 싶다.
Approach / Methods
Quantization
K-Means
- Song Han, Huizi Mao, and William J. Dally. “Deep Compression: Compressing Deep Neural Network with Pruning, Trained Quantization and Huffman Coding”. In: CoRR abs/1510.00149 (2015). arXiv:1510.00149. URL: http://arxiv.org/abs/1510.00149.
위 논문에 나온 구현을 이용했는데, Linear initialization을 했다고 한다. 지금 봐서 이해 못하니 읽고 다시 읽자.
Modified Binarization
- Maximilian Lam. “Word2Bits - Quantized Word Vectors”. In: CoRR abs/1803.05651 (2018). arXiv: 1803.05651. URL: http://arxiv.org/abs/1803.05651.
- Matthieu Courbariaux and Yoshua Bengio. “BinaryNet: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1”. In: CoRR abs/1602.02830 (2016). arXiv: 1602.02830. URL: http://arxiv.org/abs/1602.02830.
읽고 다시 읽어야 할 듯 싶다.
Pruning
- Song Han et al. “Learning both Weights and Connections for Efficient Neural Networks”. In: CoRR abs/1506.02626 (2015). arXiv: 1506.02626. URL: http://arxiv.org/abs/1506.02626.
위 논문 구현 이용했다고 한다.
Experiments
- WMT English - German translation task로 했다.
- 압축 정도 - 성능을 비교하기 위해서 BLEU score와 압축 비율을 비교했다고 한다.
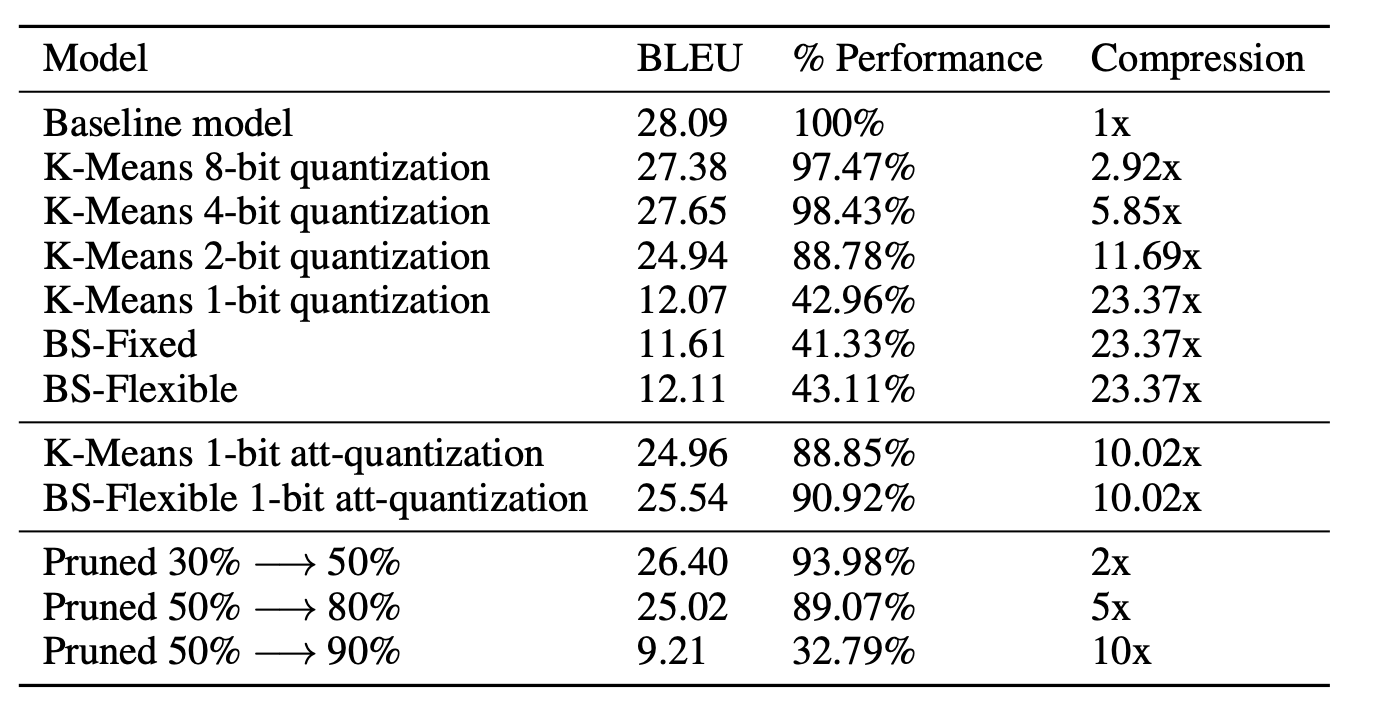
Quantitative Analysis
pruning이 생각보다 안좋았다고. quantization보다 안좋았고, Gale et al.에 있는 성능을 재현해내기 힘들었다고 한다. 90%를 없애고, 90%의 성능을 유지했다고 하는데, 그게 힘들었다고 한다. 아마 이게 이 논문에서 말하길 hyperparameter tuning이 부족해서 그런 것 같다고.
Qualitative Analysis

생각보다 4-bit까지 압축한게 엄청 성능이 좋았다고. 맨 위에서부터 원래 모델 - 8bit model - 4bit model - binarized model이다. 부록에서도 다르게 비교헀는데, 원래 모델과 8bit model, 4bit model은 거의 구분이 불가능했다고 한다.
읽을 것들
이 논문에서 뭔가를 새롭게 제시하는게 아니라 그냥 이것저것 해보고 이거 좋더라 하는 내용이라 이해하려면 다른 걸 많이 읽어보아야 할 듯 싶다. ㅠㅠ 여기서 나중에 적당히 볼 시간 되는 것만 봐야지.
- Yann Le Cun, John S. Denker, and Sara A. Solla. “Optimal Brain Damage”. In: Advances in Neural Information Processing Systems. Morgan Kaufmann, 1990, pp. 598–605.
- B. Hassibi, D. G. Stork, and G. J. Wolff. “Optimal Brain Surgeon and general network pruning”. In: IEEE International Conference on Neural Networks. Mar. 1993, 293–299 vol.1. DOI: 10.1109/ICNN. 1993.298572.
- Yunchao Gong et al. “Compressing Deep Convolutional Networks using Vector Quantization”. In: CoRR abs/1412.6115 (2014). arXiv: 1412.6115. URL: http://arxiv.org/abs/1412.6115.
- Song Han, Huizi Mao, and William J. Dally. “Deep Compression: Compressing Deep Neural Network with Pruning, Trained Quantization and Huffman Coding”. In: CoRR abs/1510.00149 (2015). arXiv: 1510.00149. URL: http://arxiv.org/abs/1510.00149.
- Song Han et al. “Learning both Weights and Connections for Efficient Neural Networks”. In: CoRR abs/1506.02626 (2015). arXiv: 1506.02626. URL: http://arxiv.org/abs/1506.02626.
- Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. “Distilling the Knowledge in a Neural Network”. In: arXiv e-prints, arXiv:1503.02531 (Mar. 2015), arXiv:1503.02531. arXiv: 1503.02531 [stat.ML].
- Matthieu Courbariaux and Yoshua Bengio. “BinaryNet: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1”. In: CoRR abs/1602.02830 (2016). arXiv: 1602.02830. URL: http://arxiv.org/abs/1602.02830.
- Fengfu Li and Bin Liu. “Ternary Weight Networks”. In: CoRR abs/1605.04711 (2016). arXiv: 1605. 04711. URL: http://arxiv.org/abs/1605.04711.
- Jacob Devlin. “Sharp Models on Dull Hardware: Fast and Accurate Neural Machine Translation Decoding on the CPU”. In: CoRR abs/1705.01991 (2017). arXiv: 1705.01991. URL: http://arxiv.org/abs/ 1705.01991.
- Yew Ken Chia and Sam Witteveen. “Transformer to CNN: Label-scarce distillation for efficient text classification”. In: 2018.
- Maximilian Lam. “Word2Bits - Quantized Word Vectors”. In: CoRR abs/1803.05651 (2018). arXiv: 1803.05651. URL: http://arxiv.org/abs/1803.05651.
- Jerry Quinn and Miguel Ballesteros. “Pieces of Eight: 8-bit Neural Machine Translation”. In: CoRR abs/1804.05038 (2018). arXiv: 1804.05038. URL: http://arxiv.org/abs/1804.05038.
- Jean Senellart et al. “OpenNMT System Description for WNMT 2018: 800 words/sec on a single-core CPU”. In: Proceedings of the 2nd Workshop on Neural Machine Translation and Generation. Melbourne, Australia: Association for Computational Linguistics, 2018, pp. 122–128. URL: http: //aclweb.org/anthology/W18- 2715.