CS231n KNN 방식의 Image Classifier
이제 Assignment 목록에 있던거 구현하기.
이건 KNN 방식을 이용한 건데, Nearest Neighbor 방식이랑 다 같은데, 가장 가까운걸 찾아서 그 중 많은 걸 고르는 방식이다. 뭔 말이냐 하면, 일단 K값이 3이라 하자. 그러면 가장 가까운 3개를 골라서 그 중 많은 걸 고른다. 만약 [1, 2, 1] 이렇게 골라졌다면, 1을 고른 거랑 똑같은 것이다.
그래서 Nearest Neighbor 방식은 K가 1일때랑 같은 것이다.
majority voting이라고 강의에서 표현을 하던데, 이러한 방법을 사용하기 때문에 K값은 보통 짝수보다, 홀수로 정한다고 한다.
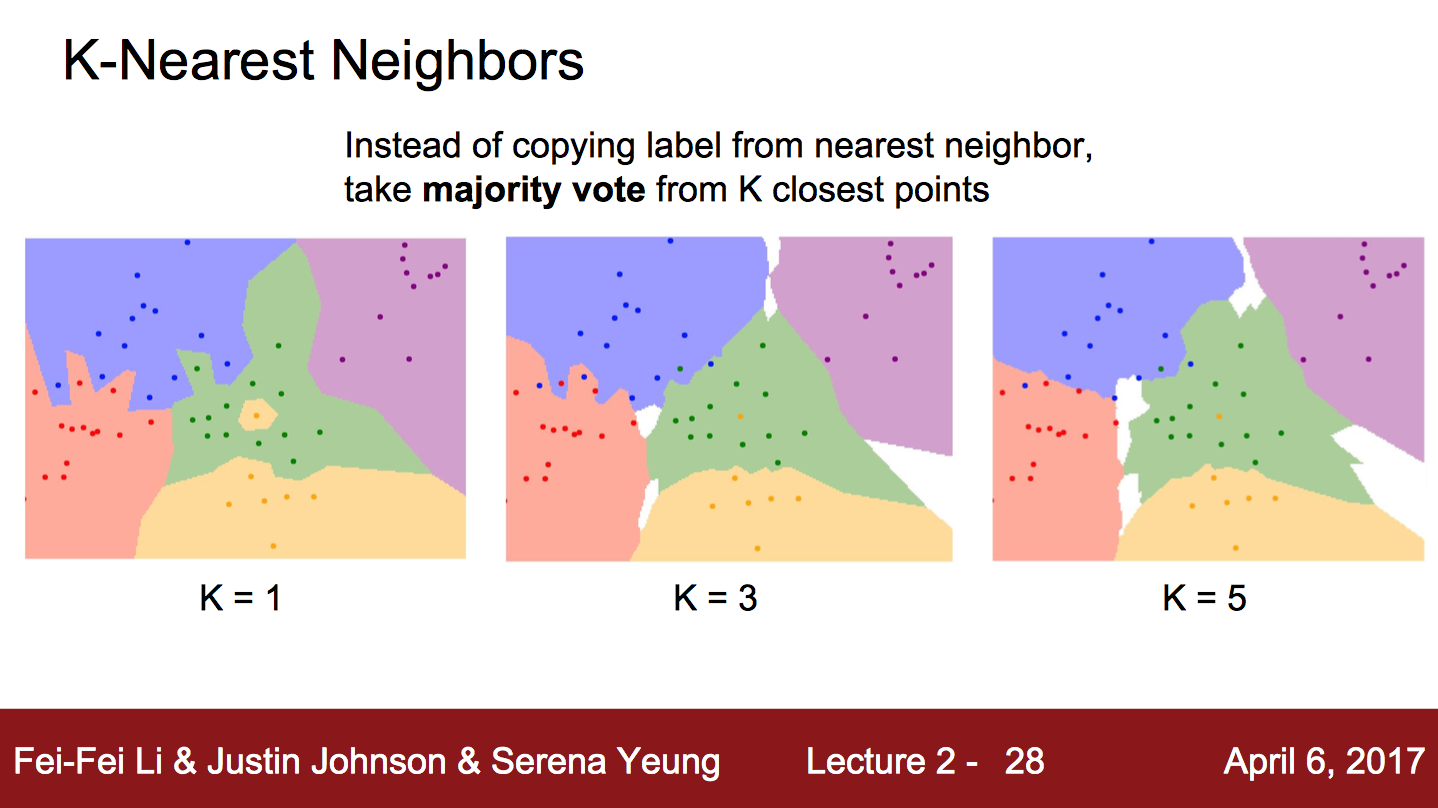
K 값이랑 Distance 정하는 방법은 적당히 사용자가 골라라고..
그래서 일단 구현을 한 후 설정을 바꿔가며 결과값을 뽑아봤다.
# image classifier using KNN and cifar 10 dataset
import numpy as np
import pickle
# sort dictionary by key
def sort_key(dictionary):
keys = list(dictionary.keys())
keys.sort()
sorted_dictionary = {}
for key in keys:
sorted_dictionary[key] = dictionary[key]
return sorted_dictionary
# get batches from files
def get_batches(files, prefix=''):
# multiple files
if type(files) is list:
result = {}
for file in files:
data = {}
# unpickle batches
with open(prefix + file, 'rb') as fo:
data = pickle.load(fo, encoding='bytes')
for i in range(len(data[b'labels'])):
label = data[b'labels'][i]
if label not in result:
result[label] = []
result[label].append(data[b'data'][i])
return sort_key(result)
# a file
elif type(files) is str:
result = {}
data = {}
with open(prefix + files, 'rb') as fo:
data = pickle.load(fo, encoding='bytes')
for i in range(len(data[b'labels'])):
label = data[b'labels'][i]
if label not in result:
result[label] = []
result[label].append(data[b'data'][i])
return sort_key(result)
# Manhattan distance
def mdistance(x, y):
return np.abs(np.sum(x - y))
# Euclidean distance
def edistance(x, y):
return np.sqrt(np.abs(np.sum((x-y) ** 2)))
# function that returns majority of a list
# Example : [1,2,1,1] -> 1
def get_majority(data):
max_item = None
max_value = None
for item in set(data):
tmp = 0
for datum in data:
if item is datum:
tmp += 1
if max_value is None or max_value < tmp:
max_value = tmp
max_item = item
return max_item
# predict function
def predict(data, test, distance=mdistance):
min_label = []
min_label_value = []
for index in data:
for batch in data[index]:
d = distance(batch, test)
# always append till length of min_label does not equal K.
if len(min_label) < K:
min_label.append(index)
min_label_value.append(d)
elif max(min_label_value) > d:
i = np.argmax(min_label_value)
min_label[i] = index
min_label_value[i] = d
return get_majority(min_label)
# Hyperparameters
K = 5
D = edistance
if __name__ == "__main__":
# get batches == train
files = ['1', '2', '3', '4', '5']
images = get_batches(files, prefix='cifar-10-batches-py/data_batch_')
# get test data
test_images = get_batches('test_batch', prefix='cifar-10-batches-py/')
result = []
for test_image_index in test_images:
cnt = 0
for batch in test_images[test_image_index]:
label = predict(images, batch, distance=D)
result.append(label is test_image_index)
print("predict : %d, answer : %d"%(label, test_image_index))
cnt += 1
# check 100 images
# 10 (0 ~ 9) * 10
# edit this value to adjust the number of test images
if cnt == 10:
break
# print result
result_np = np.array(result, dtype='float32')
print("Average : %f"%np.mean(result_np))
# result
# the number of test images : 100
#
# K = 3
# using Manhattan distance function
# ---
# Average : 0.250000
# ---
#
# using Euclidean distance function
# ---
# Average : 0.220000
# ---
#
# K = 5
# using Manhattan distance function
# ---
# Average : 0.250000
# ---
#
# using Euclidean distance function
# ---
# Average : 0.200000
# ---
결과는 위의 코드에 들어가있다.
전부 100개의 테스트 이미지로 테스트를 했는데 (10000개를 전부 돌리기에는 시간이 너무 걸려서 100개만..), K값이 1이고, Euclidean 방식을 쓸 때 가장 결과가 좋았다.
Convolutional Neural Network를 쓰기 전에 연습해보는 느낌이라 정확도는 낮은 듯 하다.
August 21, 2017