CS231n Nearest Neighbor 방식의 Image Classifier
강의를 보면서 일단 먼저 나오는 것부터 구현해보았는데, Nearest Neighbor 방식의 Image Classifier입니다.

강의 슬라이드를 보면, train 과정은 단지 모든 label과 data만 기억하고, predict 과정에서는 가장 비슷한 이미지를 찾아내고 그 이미지의 label을 반환하면 된다고 한다.
저는 train을 할 때 {‘label’ : [data1, data2, data3, ..]}와 같은 방식으로 저장을 했는데, 소스코드를 보면 알 수 있을 것입니다.
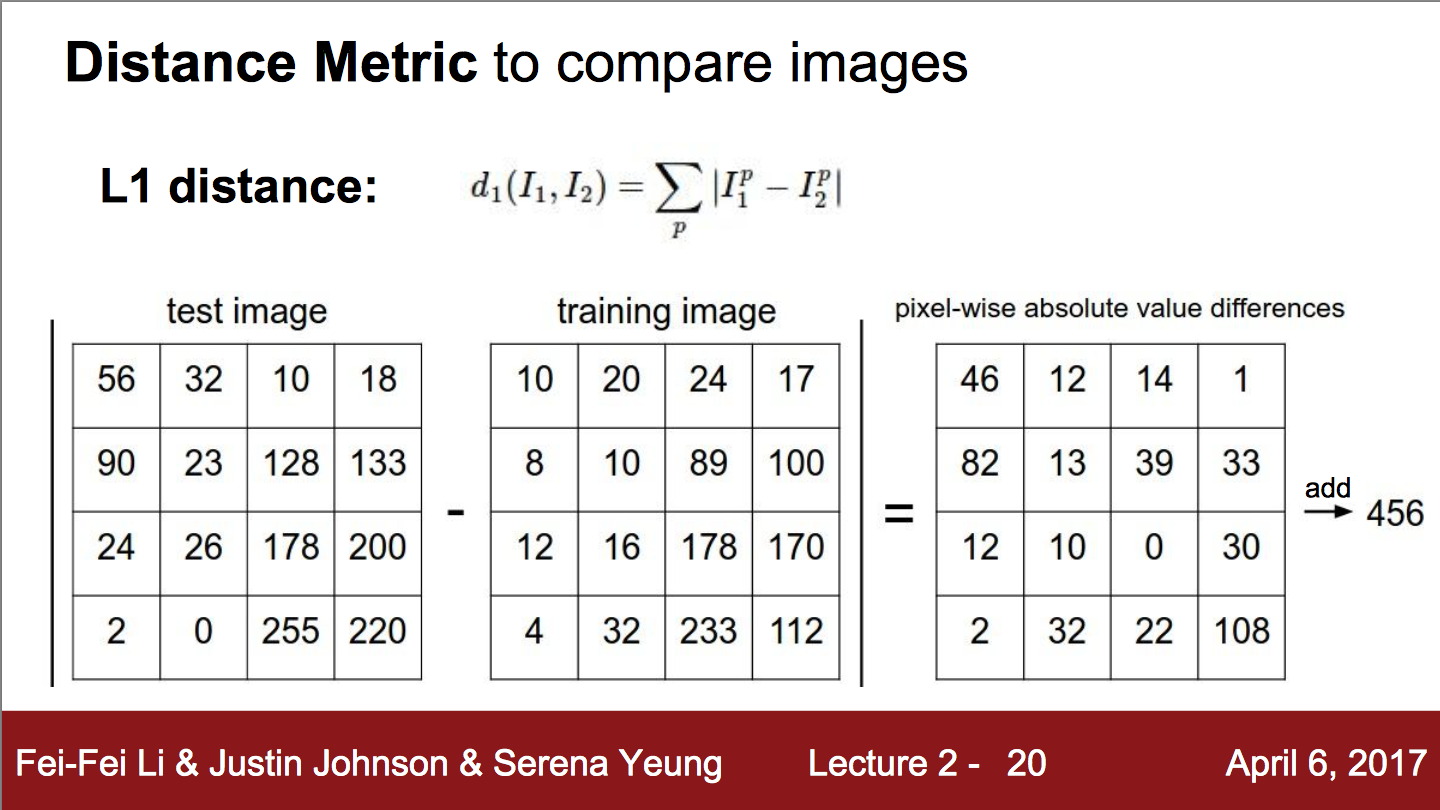
이미지를 비교하기 위한 Distance Metric은 저렇다는데, 저것만 해보긴 그래서 Euclidean distance 방법도 구현해보았고, 위의 방법은 Manhattan distance 방법이네요.
마지막 결과는 Boolean 값을 담고 있는 리스트로 결과들을 저장한 후 (맞다면 True로, 아니라면 False로) float32 형태로 변환한 후 바로 평균을 구했어요. 그렇게 한다면 바로 얼마나 정확한지에 대한 확률이 나오고, 거기에 100을 곱하면 퍼센트로 구할 수 있고.
혹시 이해가 되지 않으시거나, 제가 잘못 구현한 부분, 영어가 틀린 부분에 대해 알려주시면 감사하겠습니다.
# image classifier using nearest neighbor and cifar 10 dataset
import numpy as np
import pickle
# sort dictionary by key
def sort_key(dictionary):
keys = list(dictionary.keys())
keys.sort()
sorted_dictionary = {}
for key in keys:
sorted_dictionary[key] = dictionary[key]
return sorted_dictionary
# get batches from files
def get_batches(files, prefix=''):
# multiple files
if type(files) is list:
result = {}
for file in files:
data = {}
# unpickle batches
with open(prefix + file, 'rb') as fo:
data = pickle.load(fo, encoding='bytes')
for i in range(len(data[b'labels'])):
label = data[b'labels'][i]
if label not in result:
result[label] = []
result[label].append(data[b'data'][i])
return sort_key(result)
# a file
elif type(files) is str:
result = {}
data = {}
with open(prefix + files, 'rb') as fo:
data = pickle.load(fo, encoding='bytes')
for i in range(len(data[b'labels'])):
label = data[b'labels'][i]
if label not in result:
result[label] = []
result[label].append(data[b'data'][i])
return sort_key(result)
# Manhattan distance
def mdistance(x, y):
return np.abs(np.sum(x - y))
# Euclidean distance
def edistance(x, y):
return np.sqrt(np.abs(np.sum((x-y) ** 2)))
# predict function
def predict(data, test, distance=mdistance):
min_label = 0
min_label_value = -1
for index in data:
for batch in data[index]:
d = distance(batch, test)
if min_label_value is -1 or min_label_value > d:
min_label = index
min_label_value = d
return min_label
if __name__ == "__main__":
# get batches == train
files = ['1', '2', '3', '4', '5']
images = get_batches(files, prefix='cifar-10-batches-py/data_batch_')
# get test data
test_images = get_batches('test_batch', prefix='cifar-10-batches-py/')
result = []
for test_image_index in test_images:
cnt = 0
for batch in test_images[test_image_index]:
label = predict(images, batch, distance=edistance)
result.append(label is test_image_index)
print("predict : %d, answer : %d"%(label, test_image_index))
cnt += 1
# check 100 images
# 10 (0 ~ 9) * 10
# edit this value to adjust the number of test images
if cnt == 10:
break
# print result
result_np = np.array(result, dtype='float32')
print("Average : %f"%np.mean(result_np))
# result
# the number of test images : 100
#
# using Manhattan distance function
# ---
# Average : 0.200000
# ---
#
# using Euclidean distance function
# ---
# Average : 0.270000
# ---
August 21, 2017