Are Sixteen Heads Really Better than One? 리뷰
Multi head attention이 표현력이 좋고 많은 정보를 담을 수 있다지만, 모든 head가 필요한 것은 아니다. 이에 관한 논문이 Are Sixteen Heads Really Better Than One? (Michel et al., 2019)이고, arxiv 링크는 https://arxiv.org/abs/1905.10650이다.
Abstract
- MultiHead로 학습이 되었더라도 Test Time에는 많은 head를 제거해도 비슷한 성능을 보존하는 것이 가능함.
- 특히 몇몇 레이어는 single head여도 성능하락이 없었다.
1. Introduction
- greedy 하고 iterative한 attention head pruning 방법 제시
- inference time을 17.5% 높였다.
- MT는 pruning에 특히 민감했는데, 이를 자세히 살펴봄
2. Background: Attention, Multi-headed Attention, and Masking
- 거의 다 패스
- Multi Head Attention Masking하는 것은 mask variable로 계산함
- 특정 head의 결과값을 0으로 지정
3. Are All Attention Heads Important?
- WMT에서 테스트
3.2. Ablating One Head
- 하나의 Head만 제거하는 테스트
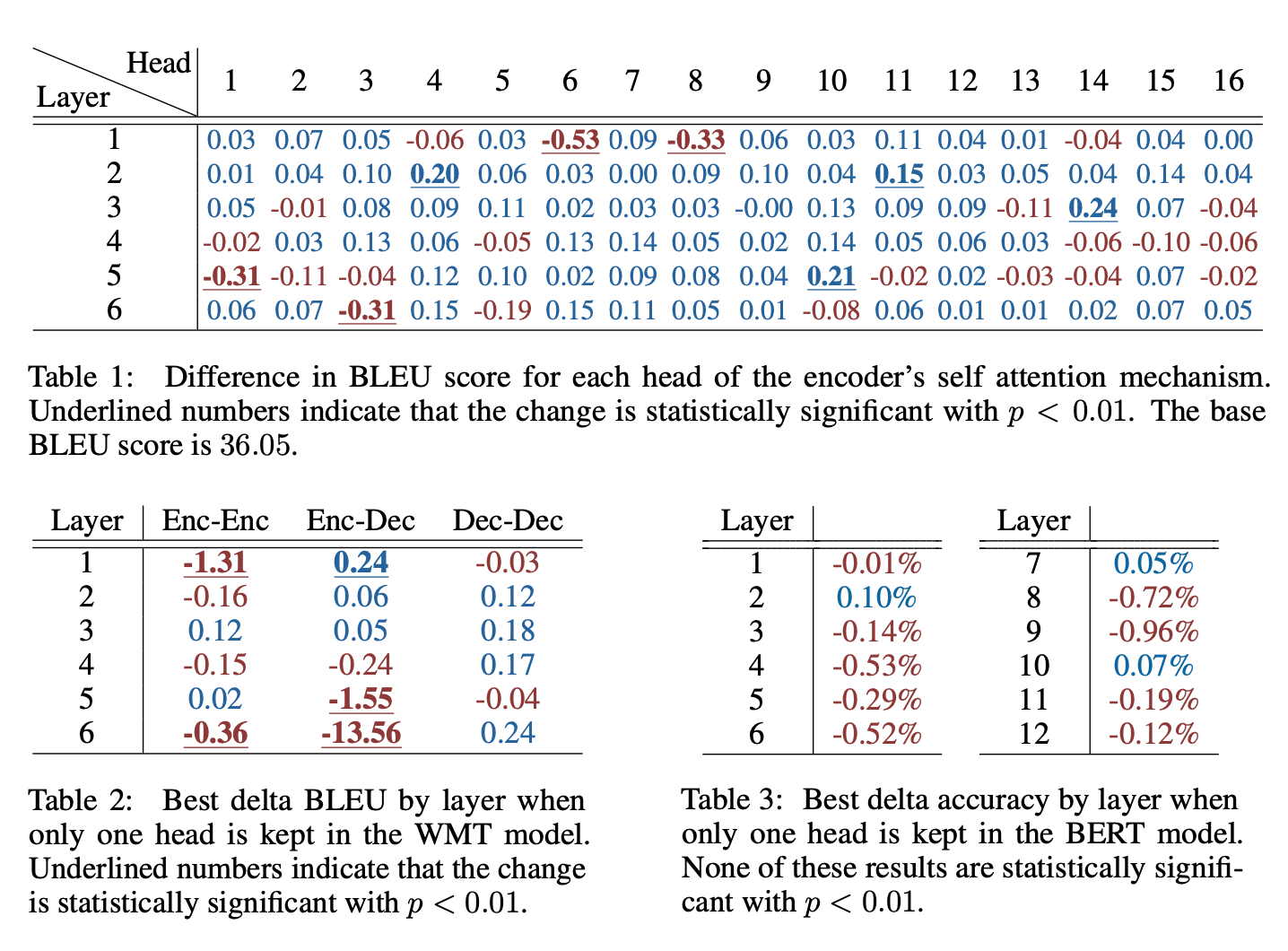
-
at test time, most heads are redundant given the rest of the model.
3.3. Ablating All Heads but One
- 그럼 head가 하나 이상 필요할까?
- 대부분의 layer는 12/16 head로 trian되었어도 test time에 1 head도 충분하다.
- 근데 NMT는 되게 민감함
- WMT에서 enc-dec의 last layer가 1 head 사용할 경우 13.5 BLEU point이상 떨어짐
- last layer가 dec의 last layer인가..?
3.4. Are Important Heads the Same Across Datasets?
- 중요한 head는 다른 태스크에서도 중요할까?
- 어느정도 중요함, 그런 경향을 보임
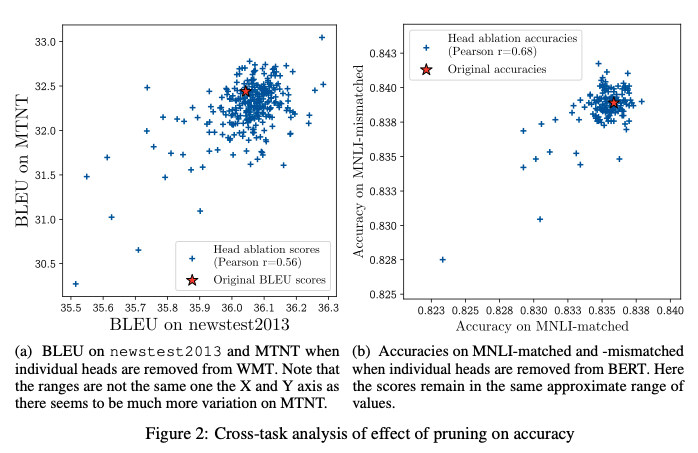
4. Iterative Pruning of Attention Heads
- iterative하게 적당히 자르자
4.1. Head Importance Score for Pruning
- head mask에 대한 loss로 계산한다.
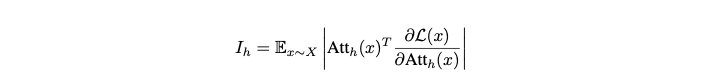
- Molchanos et al., 2017 방법을 tayler expansion한 거랑 같다
- Molchanos et al., 2017에 따라서 importance score를 l2 norm으로 정규화함
4.2. Effect of Pruning on BLEU/Accuracy
- 20% ~ 40%정도 pruning이 가능했다.
- Appendix에 더 있음
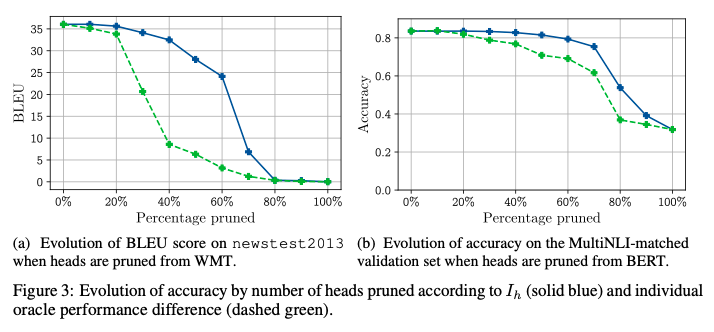
4.3. Effect of Pruning on Efficiency

- 속도는 얼마나 줄까?? 1080 ti를 가진 머신 두대에서 테스트함
- 개인적으로는 역시 pruning은 memory footprint를 줄여주는 것이 큰가?? 싶기도 하다
- 어차피 연산은 진행을 하고, 연산에서 진행하는 데이터의 크기가 주는 것이기 때문에 그렇게 dramatic한 성능 향상은 아닌 듯 함
5. When Are More Heads Important? The Case of Machine Translation
- 결론:
-
In other words, encoder-decoder attention is much more dependent on multi-headedness than self-attention.
-
- 역시 self-attention이 redundancy가 높은 건가??
6. Dynamics of Head Importance during Training
- Trained Model에서 수행하는 것보다 Training Model에서 수행하는 것은 어떤가??에 관한 것
- epoch 끝마다 각 pruning level에 따라 성능 측정해봄
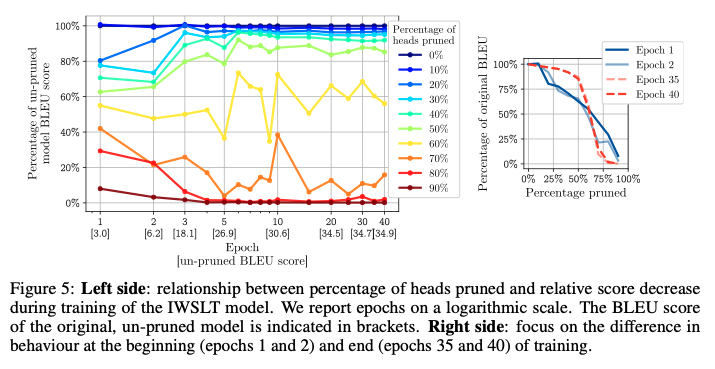
- early epoch 때는 굉장히 빠르게 성능이 하락하는데, 학습이 진행될 수록 중요한 head만 중요해지고 나머지는 아니게 됨
7. Related work
- 패스
- 근데 나중에 다시 보자
May 18, 2020
Tags:
paper