BERT 리뷰
최근에 🤗/transformers에서 다양한 transformer based model을 소개했는데, 그래서 transformer 기반의 여러 모델들을 정리해보려 한다. 첫번째로 Google의 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding를 정리해본다.
BERT는 2018년 10월에 나온 모델로 현재 오픈소스화 되어있다. (google-research/bert)
Abstract
ELMo같은 그 당시의 language representation model과는 다르게 BERT는 unlabeled text에서 right, left context를 모두 고려하게 만드는 deep bidirectional representations을 pretrain하기 위해서 설계되었다. 그를 통해 pre-trained BERT model을 fine tuning + 하나의 레이어를 얹는 것 만으로도 sota모델을 만들 수 있었다고 한다.
1. Introduction
LM을 pretrain하는 것은 그 당시에도 좋다고 여겨졌는데, (Dai and Le, 2015; Peters et al., 2018a; Radford et al., 2018; Howard and Ruder, 2018)등을 확인해보고 알 수 있다.
그런 pre-trained language representations를 downstream task들에 적용하는 방법에는 두 가지 방법이 있다. feature-based와 fine-tuning이다. feature-based는 ELMo와 같은 모델이 속하고 pre-trained representation을 추가적인 feature정도로 활용을 하고 task-specific architecture를 가져가는 방식이다. 그와 다르게 fine-tuning방법은 GPT와 같은 모델이 속하고 task-specific한 parameters를 최대한 줄이고, pretrained parameters를 fine-tuning하기만 하는 방법이다.
구글은 여기서 둘 다 같은 objective function을 사용하고 general language representation을 위해 unidirectional LM을 사용하기 때문에 pretrained reprsentation의 강력함을 전부 끌어와서 쓰지 못한다고 판단한 것 같다. 특히 fine-tuning approach에서. OpenAI의 GPT와 같은 경우에는 left-to-right architecture이기 때문에 Transformer의 self-attention layer에서 모든 token이 이전의 token들만 활용할 수 있다.
여기서는 BERT를 소개하면서 unidirectionality constraint를 masked LM을 사용하면서 해결했다고 한다. masked ML은 입력 문장에서 임의로 특정 토큰을 가리고 해당 문장만을 주고 가려진 토큰를 추측하게 만드는 방법이다. masked LM은 기존의 LM과는 다르게 양쪽의 context를 전부 활용할 수 있다. masked LM 태스크와 next sentence prediction task도 풀게 했다고 한다.
2. Related Work
2.1. Unsupervised Featrue-based Approaches
다양하게 적용할 수 있는 representation을 학습하는 것은 생각보다 오랫동안 연구되어 왔는데 word embedding을 pretrain하는 것이 modern NLP System이다. 보통 최근에는 left-to-right langauge modeling objectives가 사용되어 왔다.
ELMo를 비롯한 다양한 모델의 설명이 나오는데 나중에 읽어보는 게 그냥 더 좋을 것 같다.
- ELMo and its predecessor (Peters et al., 2017, 2018a)
- sentence embedding (Kiros et al., 2015; Logeswaran and Lee 2018)
- paragraph embedding (Le and Mikolov, 2014)
- Learning widely applicable representations
- non-neural (Brown et al., 1992; Ando and Zhang, 2005; Blitzer et al., 2006)
- neural (Mikolov et al., 2013; Pennington et al., 2014)
2.2. Unsupervised Fine-tuning Approaches
word embedding을 unlabeled text로부터 pretrained하는 방법이 Collobert and Westn, 2008부터 시작되었다. 더 최근에는 contextual token representaion을 만들어내는 sentence, document encoder를 unlabeled text로부터 pretrain시켜서 downstream task로 fine tuning을 시킨다. (Dai and Le, 2015; Howard and Ruder, 2018; Radford et al., 2018)
2.3. Transfer Learning from Supervised Learning
supervised learning으로부터 효과적인 transfer를 보여주는 것들이 있었다. (NLI에서 Conneau et al., 2017, MT에서 McCann et al., 2017) Computer Vision에서는 large pretrained model에서의 transfer learning의 중요성을 보여주기도 헀다.
3. BERT
여튼 BERT 모델까지 왔다..
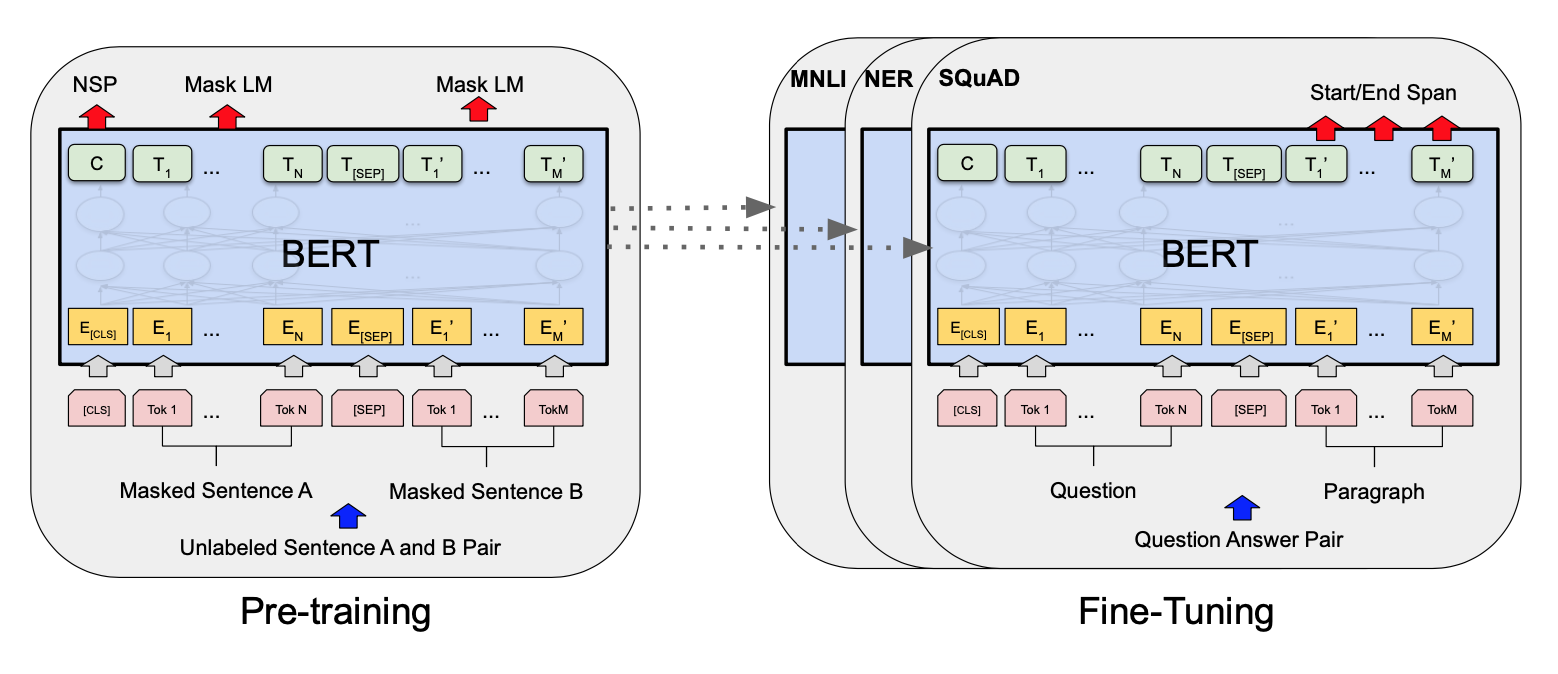
2가지 스텝이 있는데, pre-training과 fine-tuning이다. pre training에서 unlabeled data으로 학습하고 fine tuning에서 pre-training에서 학습한 모델 parameter로 초기화한 다음에 labeled data로 다시 학습한다.
Model Architecture
BERT가 다른 모델과 확실하게 구별되는 점은 다른 태스크에서도 같은 아키텍쳐를 사용한다는 점이다. 모델 아키텍쳐는 multi layer bidirectional Transformer encoder인데, Vaswani et al. (2017)에서 설명하는 것과 tensor2tensor에서 구현해놓은 것에 기반했다. The Annotated Transformer와 Vaswani et al. (2017)을 참고해보자.
BERT base와 BERT large 모델을 만들어서 테스트했다고 하는데, 그 이유는 BERT base는 OpenAI GPT와 같은 모델 사이즈로 두고 비교해보기 위해서라고 한다. 일단 두 모델의 주요한 차이점은 BERT는 bidirectioanl self-attention이 엄청 쌓여있는데 GPT는 self attention을 자기 왼쪽의 토큰들만 볼 수 있게 만들었다고.
Input Output Representation
Input/Output Representation을 downstream task를 다양하게 처리할 수 있게 만드려고 single sentence와 pair of sentence를 조금 모호하게 하나의 token sequence에서 표현할 수 있게 했다. 여기서 sentence는 실제 언어의 sentence가 아닌 임의의 연속적인 텍스트이다. sequence는 BERT에 들어가는 input token sequence를 가리킨다. (single sentence나 two sentence가 함께 들어갈 수 있다)
BERT에서는 30,000개의 단어로 WordPiece embedding을 사용했다. (Wu et al., 2016) 항상 첫번째 토큰은 [CLS]를 사용했다. 이 토큰에 해당하는 final hidden state는 classification task에서 사용할 수 있다. sentence pair는 여기서 single sequence로 들어갈 수 있는데, special token으로 분리를 한다. ([SEP])
3.1. Pre-training BERT
BERT를 두가지 unsupervised task로 학습을 시키는데 첫번째가 Masked LM이고 두번째가 Next Sentence Prediction이다.
Masked LM
LM은 보통 다음 단어를 보는데, 정말 그렇게 해야해서이지만, 그래도 deep bidirectional representaion을 학습하기 위해 일정 확률로 랜덤하게 input token을 masking했다. 그리고 Masked token을 넣었다. 이 때 final hidden vector가 그냥 LM처럼 vocab에 대한 output softmax로 전달된다고 한다. 각 sequence에서 15% 정도의 확률로 WordPiece token을 랜덤하게 마스킹했고, denoising auto-encoders (Vincent et al., 2008)과는 다르게 전체 input을 reconstructing하기보다 그냥 masked words만 predict했다.
근데 이게 downstream task에서는 좀 안맞는게 pretraining동안만 [MASK]가 나타나고 fine-tuning할 때는 나타나지 않는데, 이걸 해결하기 위해 다 [MASK]로 치환하지 않았다. \(i\)-th token이 선택되면 80%만 [MASK]로만 치환하고 10%는 랜덤으로 치환하고 10%는 바꾸지 않고 놔둔다.
그 후에 cross entropy loss를 이용해서 원래의 토큰을 predict하도록 한다.
Next Sentence Prediction (NSP)
QA 태스크나 NLI 태스크 같은 경우는 sentence 자체의 임베딩이나 LM을 잡는 것보다 sentence의 relation을 학습시키는 것이 중요하다. 이런 것을 학습시키기 위해 binarized NSP 태스크를 학습시킨다. A, B 문장이 있을 때 50%의 확률로 B는 실제로 A의 다음 문장이도록 하고 IsNext로 레이블링한다. 나머지 50% 확률로 corpus에서 랜덤하게 아무 문장이나 들고 온 후 NotNext로 레이블링한다. 간단한 태스크이지만, 최종 모델에서 97%-98%의 정확도를 달성했고, 실제로 QA나 NLI에서 이점이 있다고 한다.
NSP 태스크는 Jenite et al. (2017)이나 Logeswaran and Lee (2018)에서 사용한 representation-learning objectives와 관련이 있다.
Pre-training data
BooksCorpus (800M words, Zhu et al., 2015)를 사용했고, English Wikipedia (2,500M words)를 사용헀다. 위키같은 경우는 list, table, header같은 정보는 전부 무시하고 text passage만 사용했다고 한다.
3.2. Fine-tuning BERT
적당한 input, output으로 바꿔주기만 하는 것으로도 괜찮게 downstream task로 fine-tuning을 할 수 있다고 한다. 그래서 해당 태스크는 엄청 빨리 끝나는데, single Cloud TPU에서 1시간이면 끝났다고 한다.
4. Experiments
이게 의미가 있긴 하지만, 따로 정리할 필요성은.. ㄴㄴ
5. Ablation Studies
Bert base에서 NSP 없이 한거랑 Masked LM 말고 Left-to-Right LM한 거랑 거기에다가 BiLSTM 레이어 얻은 거랑 다 비교해봤는데 Bert base가 제일 좋은 점수를 냈다.
그리고 LTR, RTL 모델 두개를 만들어서 연결하는 것보다 (ELMo처럼) 그냥 bidirectional model을 구성하는 것이 더 좋다고. 훨씬 cost가 적고, QA와 같은 경우에는 RTL은 적절하지 않다는 것이 그 이유다. Answer를 보고 Question을 보는 것은 이상하니까..?
그리고 모델사이즈를 증가시켜보기도 헀는데, 보통은 다들 모델 사이즈가 크면 계속해서 향상이 이루어질 것이라고 생각했지만, 이걸 small scale task로도 scaling to extreme model size -> large improvement로 이루어지는 것을 처음으로 보여주었다고 한다.
5.3. Feature-based Approach with BERT
fine-tuning말고 featrue based로 사용을 할 수 없을까? 라고 생각했는데, 물론 나왔다. 모든 태스크가 Transformer encoder 레어어로만 나타낼 수는 없을 것이고, task specific model architecture가 필요할 것이다. 또 큰 연산을 BERT로 미리 precompute해놓고 cheaper model에서 다시 간단하게 돌려야 하는 경우도 있을 것이다.
그래서 하나 이상의 레이어의 activation을 뽑아서 그걸 돌려봤는데, 그것도 나름 괜찮은 성능이었다고 한다. -> BERT는 두 가지 방법 다 쓸만한 모델이라고. (근데 이거는 최근의 자료를 보는 게 더 정확하지 않을까?)
6. Conclusion
이것도 간단하게 쓰여있어서.. 패스..