CS224n Lecture 3 Neural Network
CS224n 세번째 강의를 듣고 정리한 포스트!!
Introduction
앞으로 진행할 강의:
- 2주차: neural network (3, 4강)
- 3주차: nlp (ex> dependency parsing) (5, 6강)
HW2(gradient derivation of word2vec, implement word2vec with numpy)도 있다!
Classification Review
classification에 대한 리뷰. 일단, \(\{x_i, y_i\}_{i=1}^N\) 이 있다고 가정. (training set consisting of samples) \(x_i\)는 input, \(y_i\)는 label이다.
여기서 전통적인 ML, 통계학의 접근법은 softmax, logistic regression을 통해 decision boundary를 정하는 문제로 본다. 그래서 아래와 같은 x에 대한 식이 만들어진다.
\[p(y|x) = \frac {\exp {w_y x}} {\sum_{c=1}^C \exp w_c x}\]이거를 \(w_y x = f_y\)로 보고 표기도 가능하다. 그래서 softmax 식을 \(softmax(f_y)\)라 표기하기도 한다.
Cross Entropy Loss
\(y\)의 prob을 maximize한다. (아래 식, negative log prob을 minimize한다)
\[- \log p(y|x)\]cross entropy error는 \(p\)가 실제 확률 분포이고, \(q\)가 모델에서 계산한 확률 분포일 때, 아래 식과 같다.
\[H(p, q) = - \sum_{c=1}^C p(c) \log q(c)\]\(p\)가 one-hot vector이면 (실제로 옳은 label은 보통 하나를 선정해놓으니?), q 하나만을 계산한다. 그리고 아래는 cross entropy를 전체 데이터셋에 대해 계산한 결과이다.
\[J(\theta) = \frac 1 N \sum_{i=1}^N - \log \frac {\exp f_{y_i}} {\sum_{c=1}^C \exp f_c }\]Neural Net Classifier
softmax는 decision boundary만 제공하는데, softmax만 사용하기에는 효과적이지 않다. 그래서 neural net을 같이 쓴다. NLP에서의 classification은 word vector를 학습하면서 classification에 필요한 weight까지 학습한다. (보통은 weight만 학습)
\[\nabla_\theta J (\theta) = \pmatrix {\nabla W_1 \\ ... \\ \nabla W_d \\ \nabla x_{first word} \\ ... \\ \nabla x_{last word}} \in \mathbb R ^{Cd + Vd}\]중간에는 아는 내용이라 건너뜀. (일반적인 neural net 설명)
non linearity는 워낙 다들 강조하는 내용. 그 이유? 결국 식을 다 전개하면 하나의 층을 쌓은 것이 되므로, non linearity를 만들어주어야 한다.
NER (Named Entity Recognition)
NER은 텍스트에서 특정한 단어들을 찾고 분류하는 작업이다. 그래서 크게 두 단계로 나눌 수 있는데, 단어를 찾는 것이 1, 그를 분류하는 것이 2이다. 근데 NER을 수행하다보면 문제점이 있다. 예를 들어 future school이라는 단어가 있을 떄, 학교의 이름이 Future School인지, 아니면 정말 미래의 학교인지를 나타내는지 문맥을 모르면 알 수 없기 때문에 너무 모호하다는 문제점이 있다. 즉, context에 의존적이다.

Binary Word Window Classification
context에서 모호함이 생기니, context window와 함께 단어를 분류하자는 것이 메인이 되는 아이디어이다.
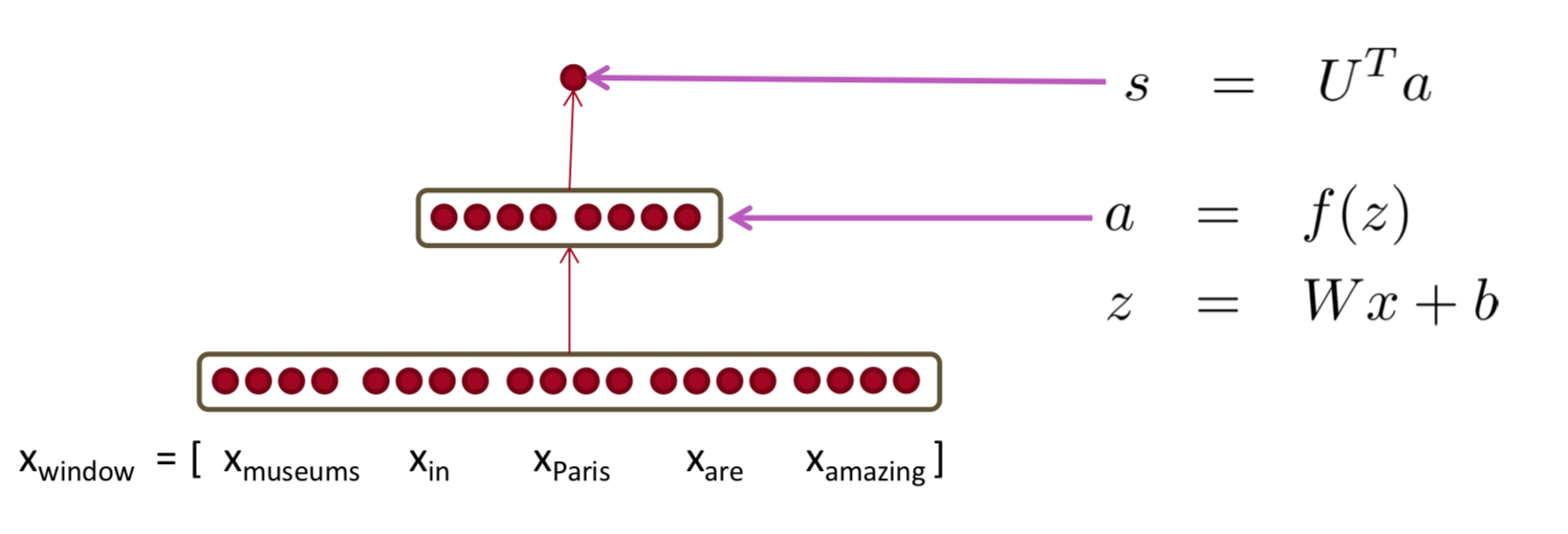
이에 대한 자세한 내용은 Collobert & Weston (2008, 2011)를 찾아보자.