CS224n Lecture 6 Language Models and RNNs
CS224n 여섯번째 강의를 듣고 정리한 포스트!
Language Modeling
Language Modeling이란 이후에 어떤 단어가 나올지 예측하는 태스크이다. 조금 더 정확하게 말하자면, \(x^{(1)}, ..., x^{(t)}\)의 단어가 주어지면, 다음 단어 \(x^{(t+1)}\)의 확률 분포를 예측하는 태스크이다.
n-gram language model
n-gram이란? a chunk of n consecutive words
ngram language model이란? collect statistics about how frequent different ngrams are, and use these to predict next word.
이게 무슨 말이냐면, 아래같은 식으로 처리한다는 말이다.
\[\begin{align}P(x^{t+1}|x^t, ... , x ^{t-n+2}) &= \frac {P(x^{t+1}, .., x^{t-n+2})} {P(x^t,...,x^{t-n+2})}\\ & \approx \frac {count(x^{t+1}, .., x^{t-n+2})} {count(x^{t}, .., x^{t-n+2})} \end{align}\]근데 여기서 문제점이 몇가지 있다.
- N개의 단어 밖에 있는 단어들을 고려하지 못한다.
- sparsity problem
- 갯수가 0개면..?
- denominator도 0이면? -> N을 1 줄여서 다시 적용한다.
- 나타나긴 나타나지만, 너무 조금 나타나서, 적절하다고 판단이 불가능할때
- storage problem
- corpus 안의 모든 갯수를 보존해야한다.
그래도 이 모델을 기반으로 text를 만들어보면 생각보다 grammatical하다. 근데, incoherent하다.
Neural Network Language Model
fixed window neural network를 사용해야하나?? -> 예측할 단어의 N개의 단어를 들고와서 임베딩 한 후 모델에 넣어서 다음 단어를 예측한다??
- sparsity problem이 없다.
- 모든 갯수를 보존할 필요가 없다.
- fixed window가 작다면?
- large window를 쓴다면 어떤가? -> weight matrix가 너무 커진다.
- 그래서 작게 유지한다면? -> 의미있는 context를 잃게 된다.
- symmetry하지 않다.
- 같은 단어가 다른 위치에 나타난다면, 다르게 처리된다.
RNN
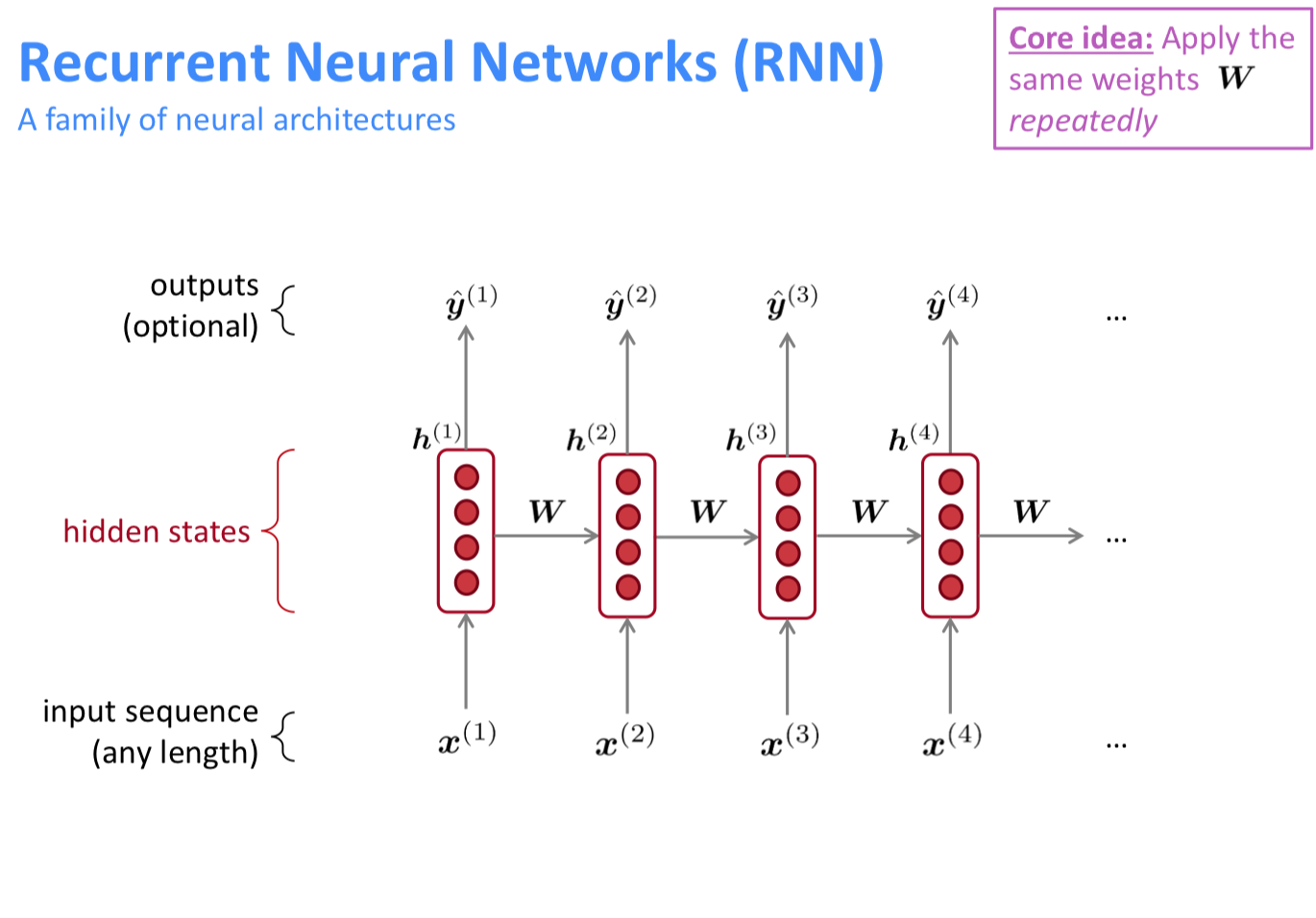
core idea가 중요하다!!
그럼 RNN을 사용했을 때 중요한 점들은?
- 어떤 길이의 텍스트이던 계산 가능하다
- 그 이전의 정보들을 활용할 수 있다.
- 모델 사이즈가 고정되어 있다.
- symmetry하게 처리 가능하다.
근데,
- 느리다.
- 그 이전의 정보를 활용하기는 사실상 힘들다.
Training RNN
큰 corpus안에서 \(\hat y\)를 계속 연산해서 훈련한다. cross entropy를 사용한다고 한다. 근데 이게 너무 연산량이 많아서, SGD처럼 미니 배치같은 개념을 차용하는 것 같다.
어찌되었든 RNN을 통해 만들어낸 텍스트는 생각보다 잘 동작하지만, 기억하는 부분과 관련해서는 좀 모자라다. 자세한 것은 medium 글을 참고해보자.
Evaluating
perplexity를 기준으로 평가한다. 값은 낮은 것이 좋다.