CS224n Lecture 7 Vanishing Gradients, Fancy RNNs
CS224n 일곱번째 강의를 듣고 정리한 포스트! 지난 강의는 RNN에 관한 것이었고, 7강은 RNN의 variants에 관한 것이다. (LSTM, GRU, …) 다음에는 NMT, seq2seq + attention 정도를 배운다.
Vanishing Gradient Problems
RNN은 같은 weight matrix를 사용해서 계산으 ㄹ하는데, 만약 gradient가 작을 경우 gradient signal은 일반적인 딥러닝에서의 네트워크보다 훨씬 빠르게 작아질 것이다. hidden state를 \(h(t)\)라 할 때 아래와 같다.
\[h(t) = \sigma (W_h h(t-1) + W_x x(t) + b)\] \[\frac {\partial h(t)} {\partial h(t - 1)} = diag (\sigma ^\prime (W_h h(t-1) + W_x x(t) + b)) W_h\]그래서 \(W_h\)가 작으면 gradient가 정말 빠르게 작아진다. 조금 더 정확하게 얘기하자면 1 weight matrix의 가장 큰 eigen value가 1보다 작으면 exponential하게 줄어든다. 1보다 커도 exploding한다. 이런 문제가 있으니 gradient signal은 가까운 곳에서 받아오도록 하자.
gradient는 미래에 대한 과거의 영향으로 볼 수 있는데, vanishing gradient 문제가 있을 경우 long distance dependency의 연결 고리가 약해지는 것과 같으므로, 해당 dependency를 학습하지 못한다.
RNN-LM을 예시로 보자. The writer of the books ____을 보고 빈칸을 예측하는 task를 풀어야 하는데, long distance dependency를 잘 학습하지 못할 경우 sequential recency를 보고 (books를 보고) are를 정답으로 낼 수 있다. 잘 학습이 된 경우에는 writer를 보고 (syntactic recency를 보고) is를 정답으로 낼 수 있다.
근데 Vanishing Gradient 문제만 있을까? -> 아니다! Exploding도 문제다! SGD가 large step을 취하고, long distance로 갈수록 Gradient가 Inf or NaN이 된다.
그래서 Gradient clipping하는 방법을 선택한다. 이것에 대한 더 자세한 해설은 Deep Learning 책의 Chapter 10.11.1을 참고하자. 결론적으로 RNN에서 timestamp를 거듭하며 학습하기가 많이.. 힘들다. -> 그럼 local memory를 사용해보면 어떨까?
다른 방법으로는 DenseNet처럼 중간중간에 dense connection을 만들어 주는 방법이 있다. 그래도 RNN은 다음과 같다고 한다.
Though vanishing/exploding gradients are a general problem, RNNs are particularly unstable due to the repeated multiplication by the same weight matrix [Bengio et al, 1994]
RNN의 변종
LSTM
LSTM은 step \(t\)에 대해서 hidden state \(h^t\)와 cell state \(c^t\)를 가진다. 그리고 이 \(c^t\)를 제어하기 위해 forget gate, input gate, output gate를 만들었고, 이 들의 계산 결과로 cell state가 제어된다.

GRU
GRU는 LSTM보다 좀 더 간단한 형태의 네트워크로, cell state가 없고, update gate와 reset gate만 사용한다. 2
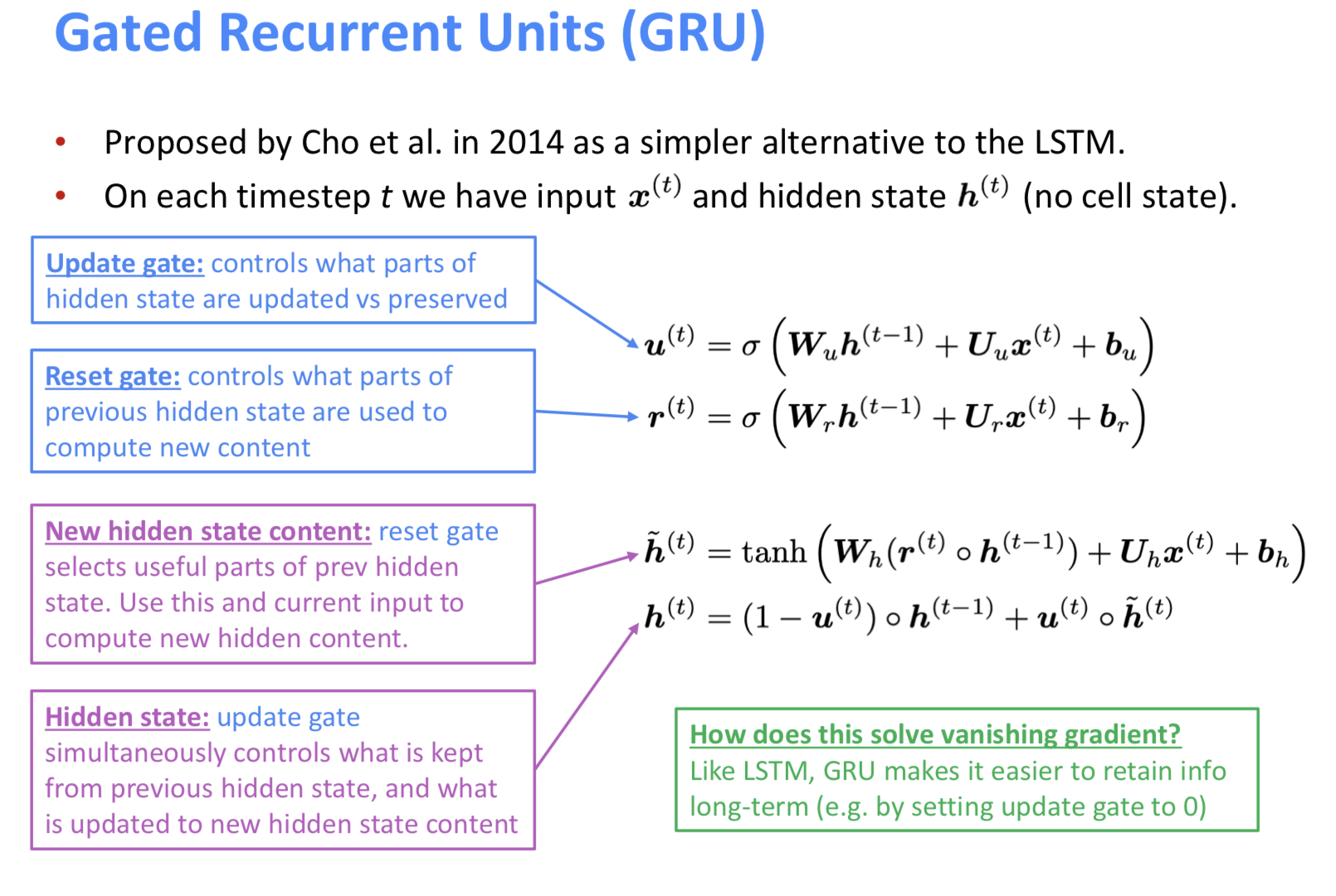
그 둘의 비교
- 둘다 오래 기억하기 좋음
- 암튼 딴 것도 많지만, 이게 그 때에는 sota를 많이 찍었다.
- GRU는 파라미터 좀 더 적게 해서 학습하기 좋고, LSTM은 그냥 기본적으로 선택하기 좋다.
- Rule of thumb에 따라서 LSTM으로 시작해본 후 efficient함을 원하면 GRU를 시도해보길 권한다고 한다.
Bidirectional RNNs
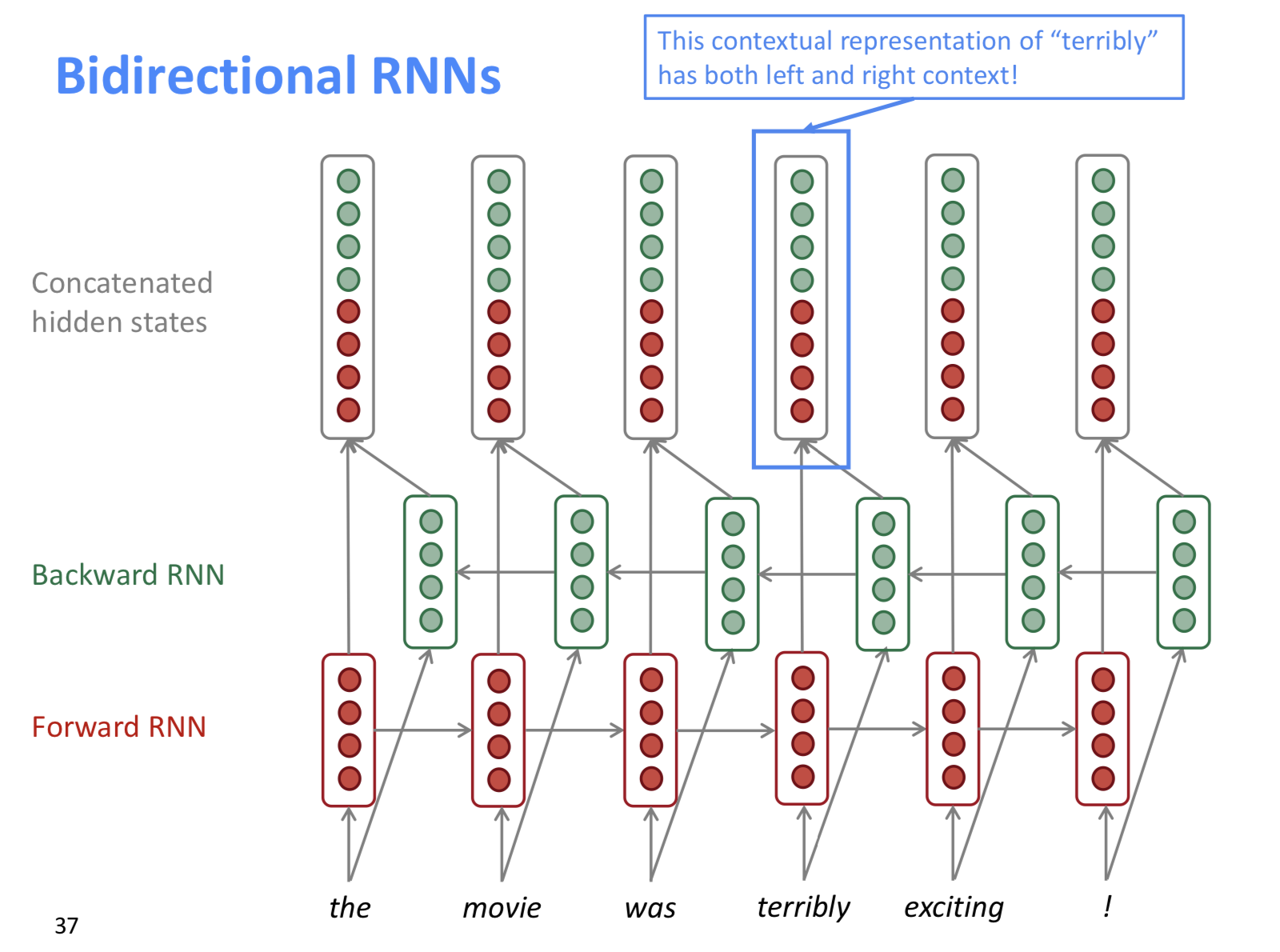
“the movie was terribly exciting!”이란 문장은 terribly가 보통 부정으로 쓰이지만, exciting 때문에 긍정으로 쓰일 수 있다. 앞 뒤 문맥이 고려가능해지지만, 전체 corpus에 대해서 접근가능할 때 쓸 수 있다. -> LM모델에선 못쓴다. 최근에 BERT라는 모델이 있는데, 정말 이것저것 다 sota찍고 있다고.3
MultiLayer RNN
하나의 weight matrix로 계속 곱해가니까 이미 어느 방면으로는 충분히 deep하다! 하지만, 그 외의 차원으로도 deep하게 만들어 준다. 조금 더 고차원의 패턴, 복잡한 표현을 잡아낼 수 있다.
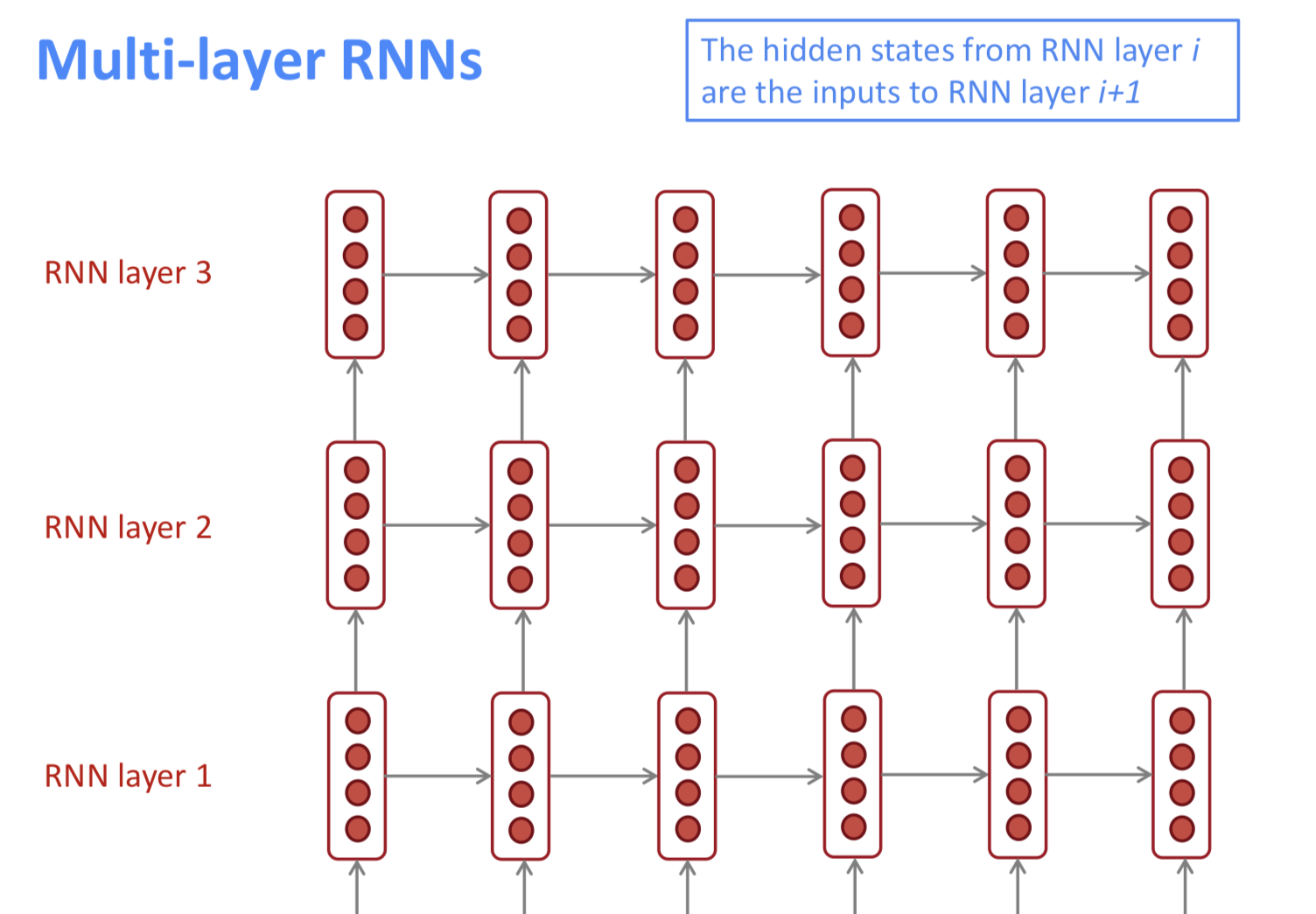
보통 2개에서 4개정도의 layer를 쌓기도 한다. transformer based network는 24 레이어까지 쌓기도 했다고 한다. 근데 이것도 역시나 gradient가 잘 전달안되는 문제점이 있어서 skip connection 같은 것을 만들어 주는 트릭이 있다고 한다.
-
https://arxiv.org/pdf/1211.5063.pdf On the difficulty of training Recurrent Neural Networks라는 제목의 논문으로 7강의 suggested readings 3에 있었다. ↩
-
https://arxiv.org/pdf/1406.1078v3.pdf 강의 슬라이드에 링크가 걸려있었는데, 뭔지 모르니까 나중에 읽어봐야지 ↩
-
https://arxiv.org/abs/1810.04805 bert 논문 ↩