CS224n Lecture 8 Machine translation, Seq2seq, Attention
CS224n 8번째 강의를 듣고 정리한 포스트! machine translation에 대해 살펴보고 seq2seq와 attention을 살펴본다.
Machine Translation
Pre-neural translation
일단 기계번역은 source language의 말들을 target language의 말로 옮기는 태스크이다. 1950’s까지는 대부분 rule base로 구현했다. (사전을 이용한 mapping이 많았다) 1990’s - 2010’s statistical machine translatin 방식을 사용했다. data로부터 probability model을 사용했고, 이를 SMT라고 줄여부른다.
\[argmax_y P(y|x) = argmax_y P(x|y)P(y)\]\(P(x|y)\) 가 translation model이고 \(P(y)\)가 LM이다. 이러한 모델을 사용하면 정말 많은 데이터가 필요하다..
alignment
SMT에서는 alignment를 학습해야한다. \(P(x,a|y)\) 로 나타내고, word를 매핑하고 나서 각각의 언어에 맞는 어순으로 배열하기 위해 alignment를 따로 학습한다.

근데 어떤 단어들은 counterpart도 없고, align을 하는 것이 “one to many”, “many to many”, “many to one” 등등 실제로 매핑되지 않는 경우까지 너무 많아서 쉽지 않다. 확률적인 모델을 학습하는 것 자체가 모든 단어들을 돌아야 하는 것인데, 너무 계산 비용이 크다.
NMT
자 그래서 NMT(neural machine translation)을 한다.
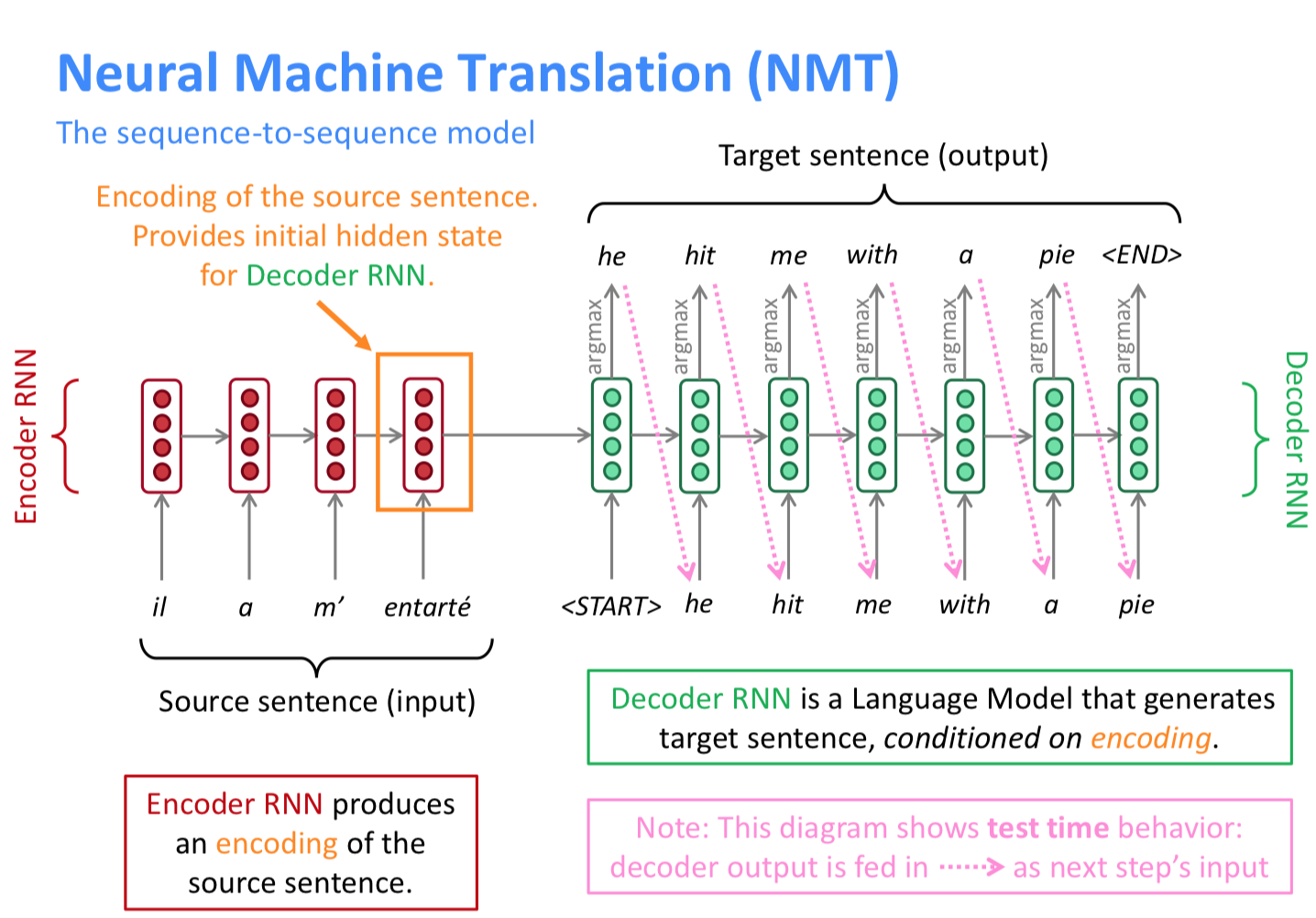
이걸 seq2seq로 풀어낸다. 잠깐 seq2seq로 푸는 문제를 말해보자면, summarization, dialogue, parsing, code generation 같은 문제들이 있다. (conditional LM의 일종)
위처럼 <END>가 나올 때까지 계속하는데, 이게 안나타나면..? 이라는 생각을 했지만, 어느정도 리밋을 둔다는 말을 들었다.
decoding을 위처럼 하는 방식이 greedy decoding인데, 이게 문제점이 있다. 앞의 것만 보고 예측을 하니 그렇게 된다.
그래서 beam search decoding 방식을 사용하는데 아래와 같은 방법이다.
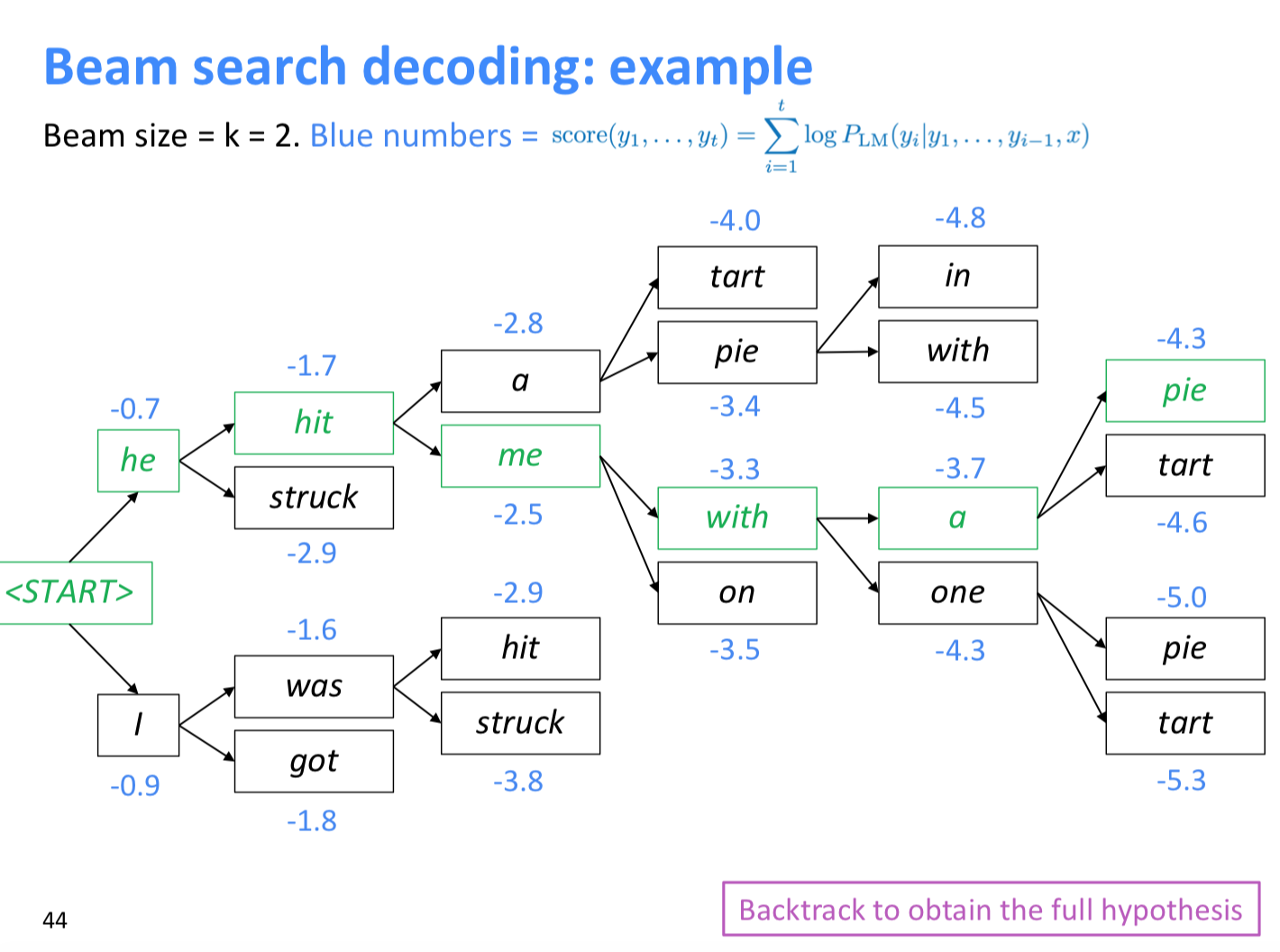
장단점
SMT와 비교해서 NMT는 많은 장점을 가지고 있다. 사람이 보기에 훨씬 fluent한 LM을 구현할 수 있고, context를 활용하는 능력 또한 뛰어나 보인다. phrase similarities를 사용하는 능력 또한 뛰어나다. 또한 subcomponent를 사용하지 않는다. SMT는 그 특성상 subcomponent를 많이 사용해야 하지만, NMT는 single neural network를 end-to-end로 최적화 하면 된다.
하지만 SMT에 비해서 디버깅이 훨씬 어렵고, 제어하기도 어렵다. 적당한 evaluation 방법 또한 없다. 그래서 BLEU를 사용하는데, 이 또한 완벽하진 않지만, 수치상으로 보여줄 만한 다른 대안이 마땅치 않기 때문에 사용한다고 한다.
BLEU
Bilingual Evaluation Understudy로, 사람이 번역한 것과 기계가 번역한 것을 우선 n-gram similarity로 스코어를 매긴다. 그리고 너무 함축하여 번역한 문장에 대해서는 패널티를 준다. 그렇게 사람이 직접 번역한 것과 기계가 번역한 것의 유사도를 판단한다.
자 그래서 잘 풀렸는가
위에서 말한 것으로 상당히 많은 문제를 해결했을 것 같지만,
- 사전에 존재하지 않는 단어는 나타내기 힘들다.
- 상당히 긴 문장에 대해서 context를 활용하기 힘들다.
- common sense를 활용하기 힘들다.
- 예를 들어서 paper jam(프린터에 종이가 끼인 것)을 실제로 종이로 담근 잼이라고 번역하는 등의 현상이 있다.
- training 데이터에 따라 bias를 가진다. 강의에서는 sex-neutral한 단어임에도 training 데이터에 따라 bias를 가짐을 보여주었다. (nurse -> she, programmer -> he??)
- 해석 불가능한 문장에 대해 임의의 문장을 뱉어낸다.
그래서 위의 문제들이 있어 더 나은 NMT를 만들고자 고안해 낸 기법이 attention이다.
Attention
seq2seq의 문제점은 encoder에서 decoder로 넘어갈 때, 하나의 hidden state만을 가지기 때문에 information bottleneck이 될 수 있다는 점이다. 그래서 이 점을 decoder의 각 step을 encoder로 직접 연결하자는 점이다.1
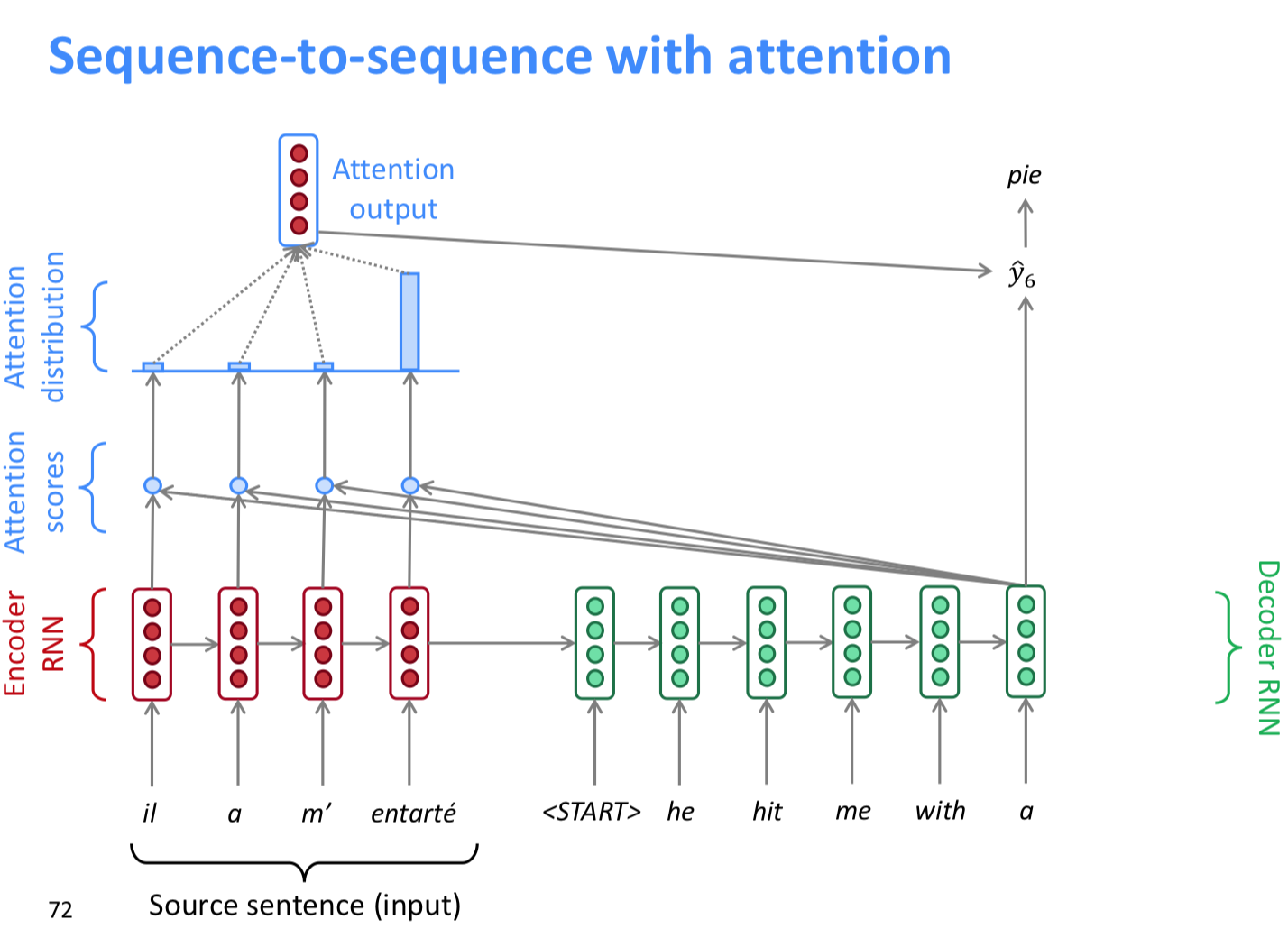
그래서 결과는
일단 가장 중요한 NMT 성능이 크게 향상되었다. 그리고 bottleneck 문제도 해결하였다. direct connection이 생기니 vanishing gradient problem도 많이 해결되었다. NMT의 단점이로 평가받던 디버그 하기 어렵다던 문제도 어느정도 풀렸다. attention을 시각화할 경우 alignment처럼 나온다.
-
https://arxiv.org/pdf/1706.03762.pdf Attention Is All You Need라는 제목의 논문으로 Attention을 제시한 논문이다. 검색해보니 CS224n의 나중의 suggested readings에 있던데 미리 읽어놓고 싶다.. ㅠㅠ ↩