DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation 리뷰
GPT를 대화체에 맞도록 학습시킨 모델이다. 마이크로소프트에서 나온 논문이고, arxiv링크는 https://arxiv.org/abs/1911.00536이다. 코드는 GitHub microsoft/DialoGPT에서 볼 수 있다.
1 Introduction
-
Like GPT-2, DIALOGPT is formulated as an autoregressive (AR) language model, and uses multi-layer transformer as model architecture.
-
Unlike GPT-2, however, DIALOGPT is trained on large-scale dialogue pairs/sessions extracted from Reddit discussion chains.
- 논문 저자들은 DialoGPT가 대화 흐름에서의 Source, Target의 joint distribution을 학습할 것을 기대했다고 한다.
- DSTC-7으로 평가했고, 6,000개의 reddit 포스팅에서 테스트 데이터셋을 뽑았다고 한다
2 Dataset
- Reddit 포스팅에서 root node -> leaf node로 가는 path를 추출해서 instance로 사용함
- 다만 아래 조건은 제외
- URL이 source, target에 있을 때
- target이 3개 이상의 단어 반복이 존재할 때
- 자주 등장하는 top 50 영단어(a, the, of)가 하나도 포함되어 있지 않을 때 -> 외국어로 생각함
- special marker가 존재할 때
[,] - source, target sequence가 200단어를 넘을 때
- 공격적인 단어를 포함할 떄
- 많이 단조로운 문장
3 Method
3.1 Model Architecture
- GPT-2, 12~24L로 세팅함
- BPE 사용
- SOURCE 문장을 다 이어붙인다음 Target 문장을 Generating하도록 작성함
3.2 Mutual Information Maximization
- Open domain text generation 모델은 bland, uninformative한 샘플을 많이 생성함
- 그래서 MMI scoring function을 사용함
- top-K 샘플링 후 Rerank
- 근데 RL 방식을 활용해서 Policy Gradient를 사용해 optimize시켜보니 local optima에 너무 잘 빠진다
- 아마 transformer의 representation power 때문인 것으로 추측
- future work로 남겨둔다 함
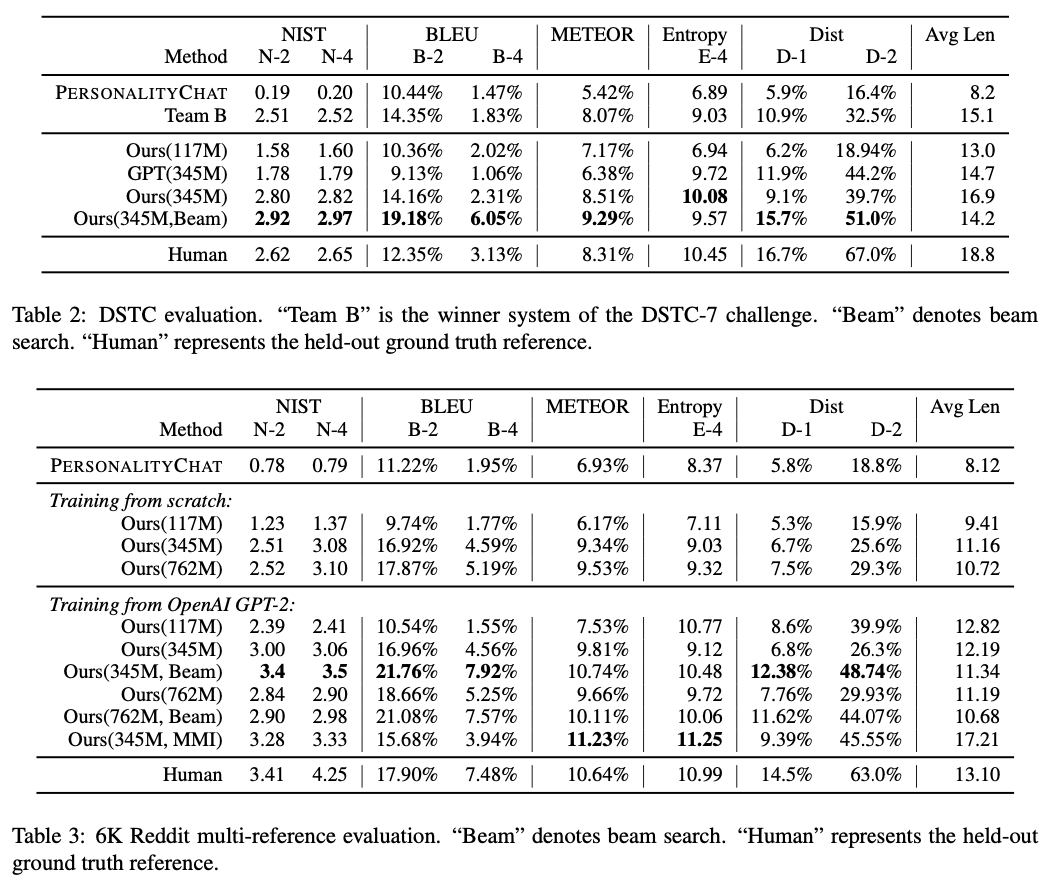
4 Result
- 117M, 345M, 762M 모델로 테스트함 세부 사항은 Radford et al. (2018)과 같음
- Azure Cognitive Service와 비교함
- Beam Search 사용하면 성능이 꽤 올라감
- 근데 grounding information이 없는데 어떻게 잘되냐? -> 아마 pretraining 동안 얻어내는 information이 많아서 grounding document없어도 괜찮은 듯 하다.
그 외엔 간단하게 읽어보면 좋을 듯
이거 샘플은 되게 신기하다


아래 결과는 진짜 놀랍다. Human Response에 버금가는 퀄리티를 생성해낸다. 다만 아쉬운 점은 345M, 762M 보여줄 거면 117M도 어느정도인지는 보여주었으면 어땠을까이다. Table 2, 3에서 그렇게 나와서 아래처럼 비교한건가??
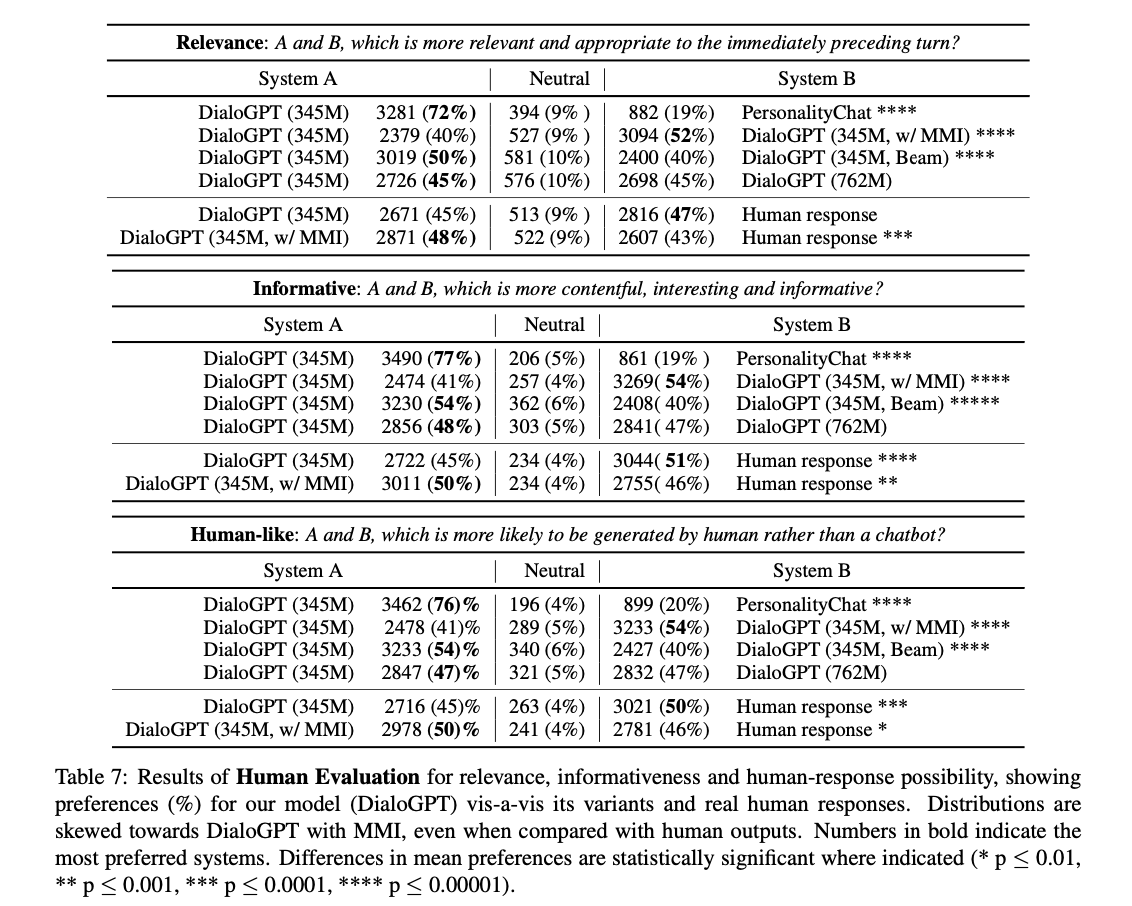
6 Limitations and risks
어쩔 수 없는 점이긴 하지만 Generation이 어느정도는 위험하긴 하니까..
Despite our efforts to minimize the amount of overtly offensive data prior to training, DI- ALOGPT retains the potential to generate output that may trigger offense. Output may reflect gen- der and other historical biases implicit in the data. Responses generated using this model may exhibit a propensity to express agreement with proposi- tions that are unethical, biased or offensive (or the reverse, disagreeing with otherwise ethical state- ments).