Efficient 8-Bit Quantization of Transformer Neural Machine Language Translation Model 리뷰
TensorFlow 상에서 FP32를 INT8로 quantization을 해보는 논문이다. 1.5배의 성능 향상을 얻으면서 0.5 BLEU score accuracy만 떨어졌다고 한다. 또한 intel cpu에 최적화를 진행했다. arxiv 링크는 https://arxiv.org/abs/1906.00532이고, intel에서 나온 논문이다.
1. Introduction
- Contributions
- Quantized a trained FP32 Transformer model to INT8 to achieve < 0.5 drop in state-of-the-art (SOTA) BLEU score.
- Improve inference performance by:
- Optimizing quantized MatMuls for tensor shapes and sizes in the Transformer model
- Reducingoverheadduetoquantizationoperations in the Transformer model compute graph
- Optimizing input pipeline by ordering sentences by token length
- Implementing parallel execution of batches with increased inference throughput
2. Related work
패스
3. Model Description
- Transformer는 scaled dot product attention 사용
- 여기서 softmax 연산이 끼여있는데 해당 연산을 quantization하면 acc loss가 높을 것이 명확.
- layer norm도 있는데 이 연산이 mean, variance를 연산하기 때문에 이것도 힘들지 않을까?
4. Quantization with accuracy
- \(scale = \frac {target} {max - min}\), \(A_{quantized} = round((A_{float} - zero_{offset}) \cdot scale)\)
- 위의 식을 따라 quantization을 진행하는데 8bit라서 min ~ max는 당연히 256의 scale을 가지게 된다.
4.1. Na ̈ıve Quantization
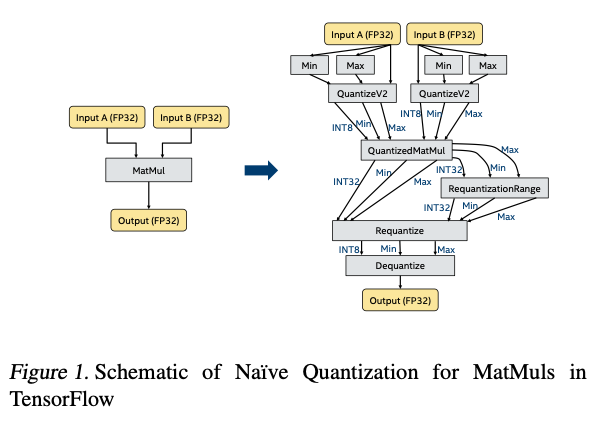
- 위의 그림과 같이 진행할 때 dequantization하는 방법: \(A_{dequantized} = (Max - Min) \cdot (A_{quantized} - zero_{offset})\)
- NMT 태스크였는데, Stop token 내뱉는데 실패해서 acc가 많이 떨어져버림
4.2. KL-Divergence for optimal saturation thresholds
- 이게 quantization이 어찌되었든 잘 매핑하는 것이 문제이다보니까 representation의 범위를 적당히 잘 줄이고 늘리는 것이 중요함
-
This relies on the assumption that maintaining small differences between tensor values that are close together is more important than representing the absolute extreme values or the outliers. Ideally, the numerical distribution of values in the mapped INT8 tensor representations should be as close as possible to the distribution of values for FP32 tensors.
- 그래서 KL Divergence 사용함
- 아이디어는 여기서 참고했다고 함 8-bit Inference with TensorRT
- calibration data로 600 랜덤 샘플링함
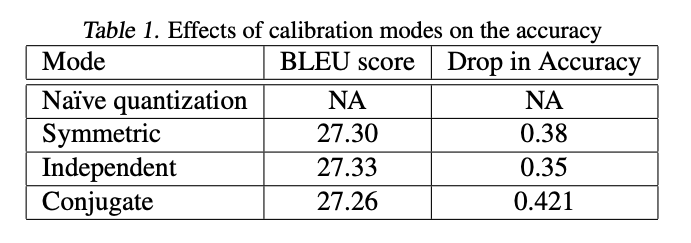
- min, max threshold를 정하는 방법을 세가지 테스트함
- symmetric하게. “threshold_min = - threshold_max”
- 독립적으로 각각 계산함
- conjugate로 계산함 (\(Threshold_{Max} = max(\vert Max \vert, \vert Min \vert)\)) 그리고 symmetric하게
- 근데 독립적으로 계산하는 것이 제일 좋음
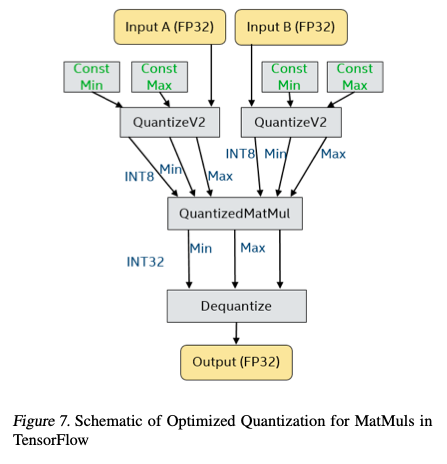
- 결국 아래처럼 quantization 진행함
5. Improving Performance
여기서부터가 이 논문에서 제일 재밌다고 생각한 부분인데, “사실상 성능을 이걸로 올린거 아냐??”라고 생각들 정도이다.
- INT8로 변환하려는 이유:
-
INT8 MatMuls using VNNI provides a speed-up of 3.7X over FP32 MatMuls using AVX512.
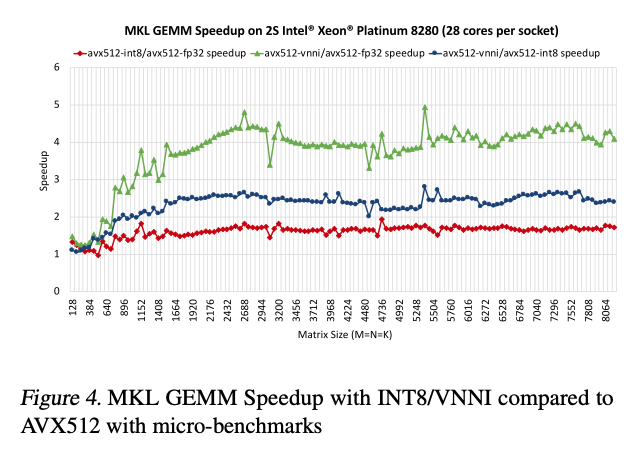
- MKL로 TensorFlow Operation직접 작성함. (아마 Custom Ops인듯?)
- TensorFlow 1.12는 GEMMLOWP라는 라이브러리를 사용하기 때문에 INT8/VNNI를 지원하지 않는다.
- 그리고 데이터 변환 과정도 필요해서 효율적이지 않다.
-
그래서 직접 작성해도 안빨라서 확인해보니까 MatMul에서 최적화 안된 부분이 있었고 그 부분을 최적화함
- 그 외에도 아래처럼 최적화함
- GatherND를 최적화했는데 그 이유는 성능 향상이 아니라 데이터 통신을 빠르게하기 위해서 진행함. 32bit보다 8bit나르는게 약 3.8x배가 빨랐기 때문
- input sentence sorting해서 연산 진행함
- Quantization 중에서 불필요한 reshape 등의 연산을 제거함
- batching을 parallel로 작성함
6. Throughput Performance Results
- 환경 셋업은 패스
- 설정만 잘해두면 병렬연산이 잘 되어서 4.5x까지 throughput 향상됨
- 근데 input pipeline 최적화한게 fp32도 최적화해버려서 결국 fp32보다 1.5x정도 빠른 연산이 되었다
7. Conclusion
We optimized the compute graph by reducing number of operations, improved kernels of key operations such as MatMuls and GatherNd, optimized order of sentences in the input pipeline and finally used parallel batching to achieve the highest throughput gains of 1.5X.
그냥 “8-bit로 연산해도 잘 된다”와 “더 최적화 가능한 부분이 많다” 정도의 논문인 것 같다. MKL로 최적화한 부분이 TF2에 적용가능한지는 모르겠다.