Fluent Bit 동작 방식 이해를 위한 노트
최근에 Fluent Bit을 살펴볼 일이 생겨 간단히 정리해본다.
-
Fluent bit은 오픈소스 Log processor 툴. 여러 상황에서도 사용할 수 있도록 개발되었다. 요즈음에는 데이터(혹은 로그)의 소스가 굉장히 다양해졌으므로, 큰 스케일에서 해당 로그들을 전부 관리하기란 매우 어려운 일이다. 여러 데이터를 수집하고 집계하기 위해서는 아래와 같은 일이 필요하다.
- Different sources of information
- Different data formats
- Data Reliability
- Security
- Flexible Routing
- Multiple destinations
Fluent Bit은 그 중에서도 특히 성능과 low resource consumption을 염두에 두고 만들어진 도구이다. Fluentd와도 많은 공통점이 있는 Fluent bit은 Fluentd의 많은 장점과 좋은 아이디어를 기반으로 개발되었다. 둘 사이의 비교는 공식 문서를 살펴보면 좋을 것 같다.
용어 (Key Concepts)
그러한 Fluent bit의 동작방식은 문서에 너무 잘 설명되어 있다. 더 잘 이해하기 위해 아래 용어 정도만 보면 좋을 것 같다.
- Event/Record: Every incoming piece of data that belongs to a log or a metric.
- 내부적으로는 Event/Record는 두개의 구성요소를 가진다. TIMESTAMP & MESSAGE
- Filtering: the process to alter, enrich or drop Events.
- 여러가지 상황에서 사용가능한데, 공식문서에서는 언급한 아래 상황들을 생각해보면 좋을 것 같다.
- Append specific information to the Event like an IP address or metadata.
- Select a specific piece of the Event content.
- Drop Events that matches certain pattern.
- Tag: an internal string that is used in a later stage by the Router to decide which Filter or Output phase it must go through.
- Match: a simple rule to select Events where it Tags matches a defined rule.
–
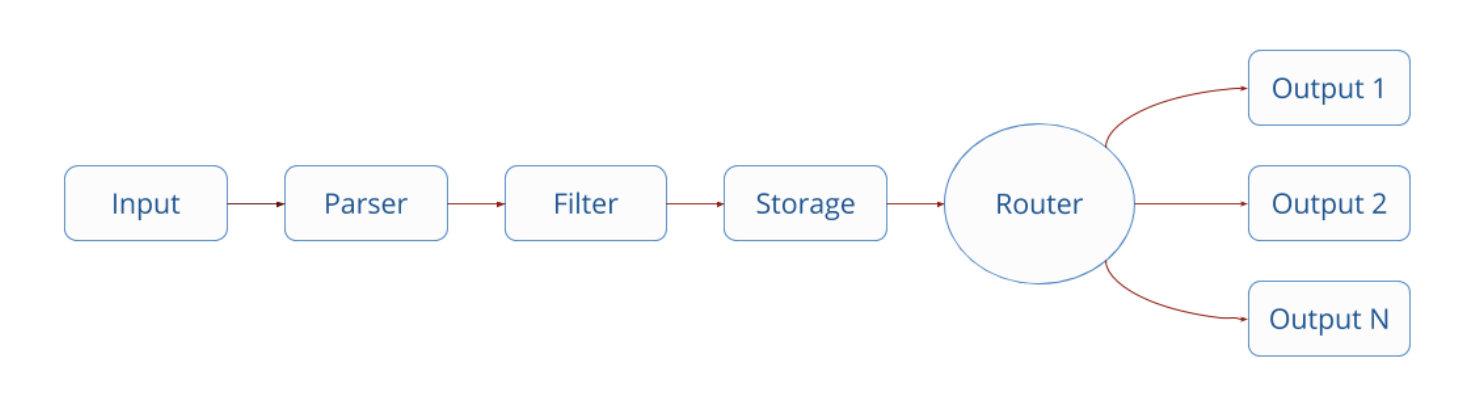
자세한 동작 방식은 아래 링크들 중 필요한 것을 살펴보면 모두 정리될 것 같다. data pipeline 문서를 따라 읽는다면 굉장히 잘 이해된다. 아래 사진을 한번 보고 가자. Input이 들어왔을 때 Output으로 가기까지의 동작 과정이다.
- What is Fluent Bit?: https://docs.fluentbit.io/manual/about/what-is-fluent-bit
- A brief history of Fluent Bit: https://docs.fluentbit.io/manual/about/history
- Fluentd vs Fluent Bit: https://docs.fluentbit.io/manual/about/fluentd-and-fluent-bit
- Key Concepts: https://docs.fluentbit.io/manual/concepts/key-concepts
- Data Pipeline: https://docs.fluentbit.io/manual/concepts/data-pipeline
이런 부분들을 공부하며 ElasticSearch, S3(로컬 테스트를 위해 Minio 활용)과 연동한 예시를 https://github.com/jeongukjae/fluentbit-demo에서 남겨두었다.
May 11, 2022
Tags:
Operation