Full Stack Deep Learning Lecture 5 ML Projects
FSDL을 듣고 읽어보며 정리한 노트입니다.
1
ML Project의 85%는 실패한다. 연구 성향이 강하기도 하고, 잘못 계획을 세우기도 하고, 매니징에 실수가 있기도 하다.
2
우선 ML 프로젝트의 라이프 사이클을 이해하는 것이 중요하니 아래처럼 정리해본다. Planning and Project Setup - Data Collection and Labeling - Model Training and Model Debugging - Model Deploying and Model Testing.
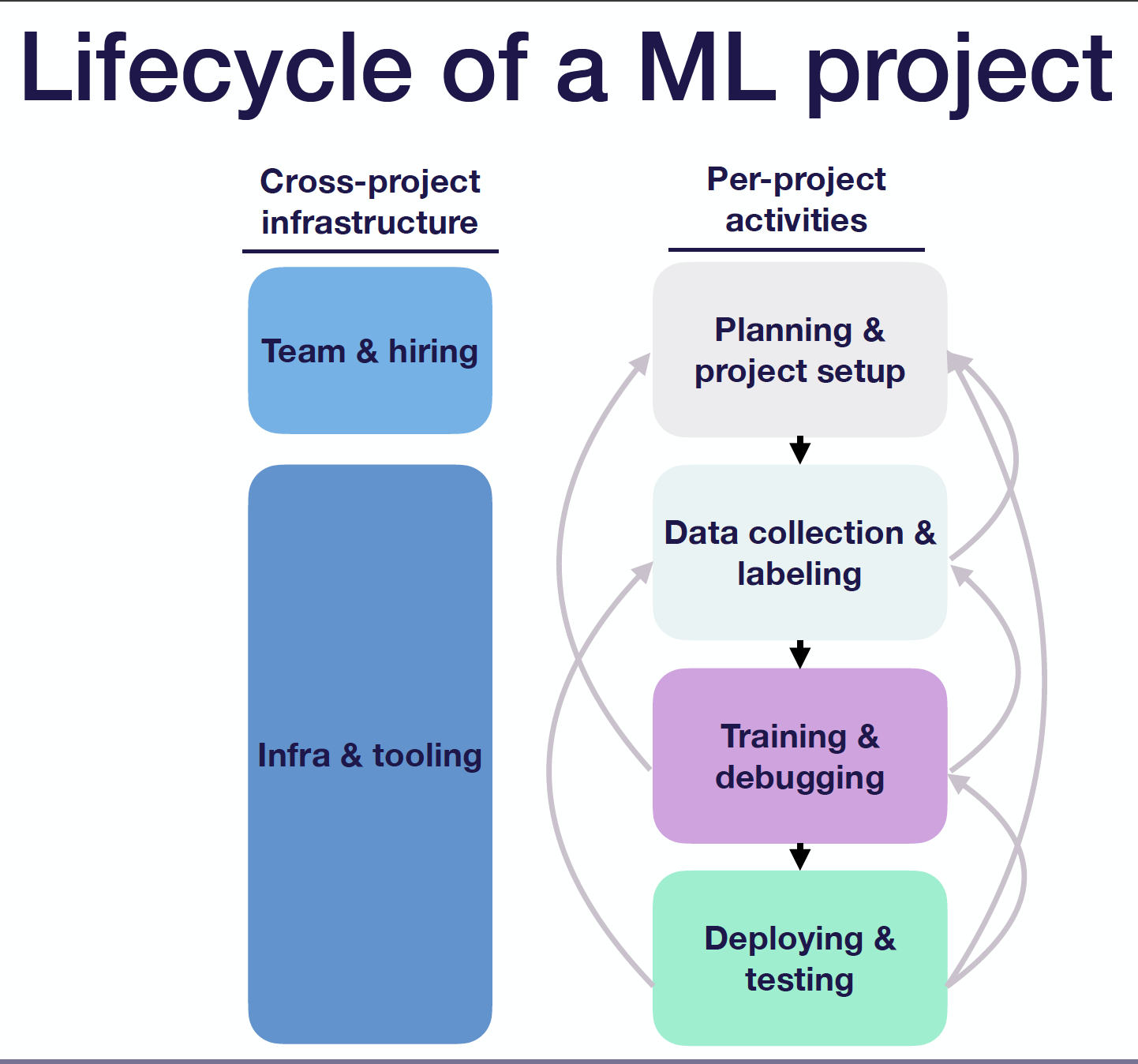
물론 ML 프로젝트 별 일도 중요하지만, Cross-project infrastructure도 중요하다. 1) 팀빌딩을 진행하고 사람들을 고용하는 것. 2) ML 시스템을 더 쉽게 구축하기 위한 인프라/도구 세팅하는 것.
3
프로젝트의 우선순위를 잘 파악하는 것도 중요하다. 높은 임팩트를 보여주는 ML 프로젝트를 어떻게 고를 수 있을까?1
- Where can you take advantage of cheap prediction?
- Where is there friction in your product?
- Where can you automate complicated manual processes?
- What are other people doing?
다르게 접근해보면 프로덕트의 니즈를 잘 파악해야한다. 2 high friction을 겪는 부분을 찾아보자. ML로 자동화를 한다면 큰 임팩트를 가져올 수 있다.
그럼 이 프로젝트들의 feasibility는 어떻게 알아볼 수 있을까? data availability, accuracy requirement, problem difficulty 순으로 살펴보자.
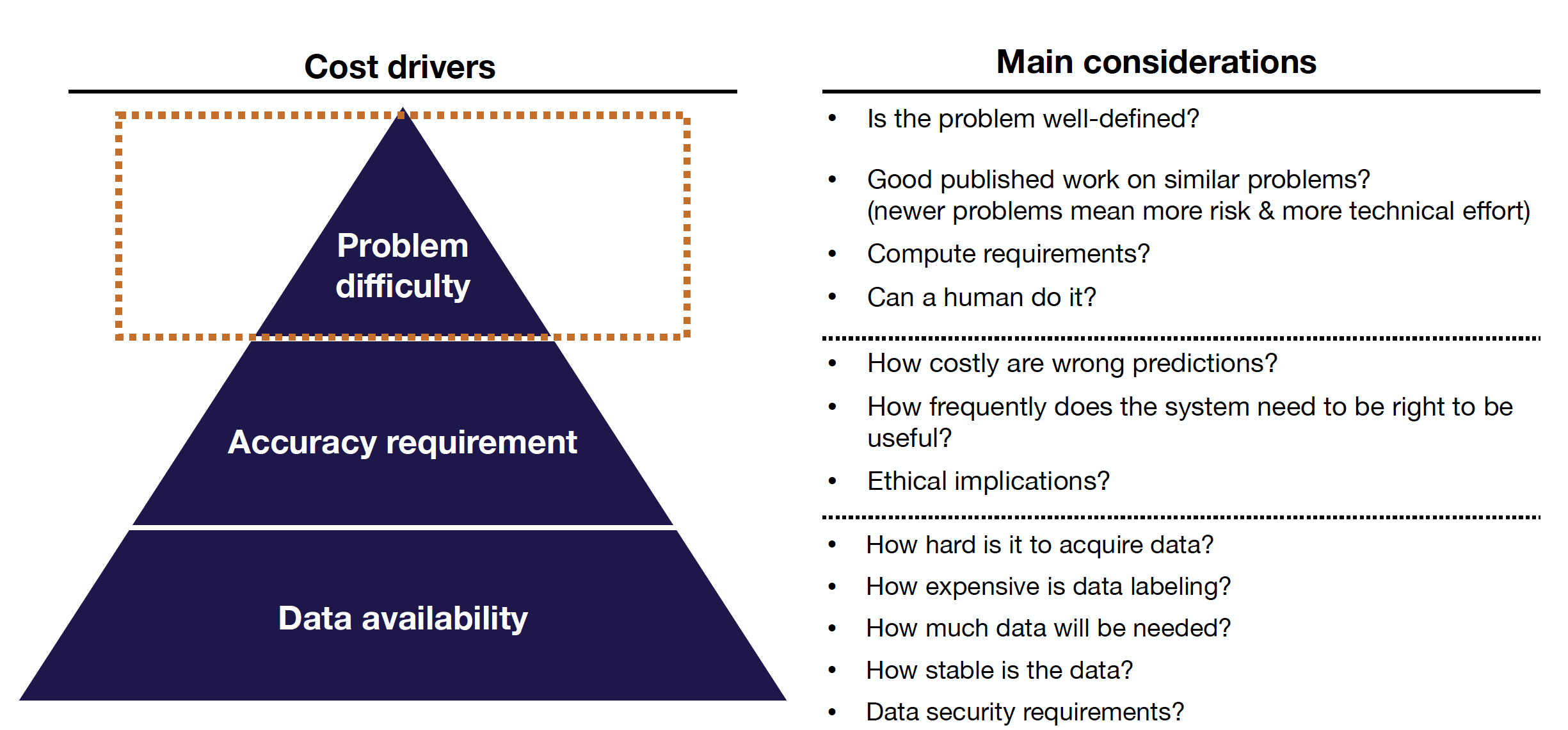
위의 세가지 주제에 대해 던져볼 수 있는 질문들이 아래처럼 있다.
- Data availabiltiy
- How hard is it to acquire data?
- How expensive is data labeling?
- How much data will be needed?
- How stable is the data?
- What are the data security requirements?
- Accuracy Requirement
- How costly are wrong predictions?
- How frequently does the system need to be right to be useful?
- What are the ethical implications?
- Problem Difficulty
- Is the problem well-defined?
- Is there good published work on similar problems?
- What are the computing requirements?
- Can a human do it?
여기서 비용은 보통 accuracy requirements에서 super-linear하게 늘어난다. 이 점을 주의하자.
4
ML 프로젝트의 Archetypes이 Karpathy가 작성한 글인 Software 2.03에 정말 잘 설명되어 있다. 여러가지 ML Archetypes이 존재할 수 있고, 한번씩 생각해보자.
Software 2.0은 더 많은 유저가 사용해서 더 많은 데이터가 쌓이고 더 좋은 모델이 나와 결국 더 많은 유저가 생기게 되는 선순환 사이클을 생각하자.
Human in the Loop는 ML 결과값을 사람이 검토하는 시스템이다. 이메일 자동완성, 스케치를 슬라이드로 바꾸어주는 작업 등등이 있을 수 있다.
Autonomous Systems는 ML 모델이 대부분의 것을 제어하고 해당 데이터가 사람의 리뷰를 거의 받지 않는 시스템을 말한다. 자율 주행 자동차를 생각해보자.
이제 이러한 Archetypes과 우선순위를 같이 고려해보자. 아래와 같은 글이 좋은 참고사항이 될 수 있다.
- https://medium.com/@Ben_Reinhardt/designing-collaborative-ai-5c1e8dbc8810
- https://developer.apple.com/design/human-interface-guidelines/machine-learning/overview/introduction/
5
ML 모델에서 굉장히 중요한 팩터 중 하나인 메트릭. 먼저 하나의 메트릭으로 만들어보자. 여러가지 메트릭이 존재하는 경우 averaging, thresholding을 통해 적절하게 하나의 단일 메트릭으로 만들어주자.
6
베이스라인을 잘 구성하자. 모델이 얼마나 잘 동작할 것인지에 대한 기본적인 기댓값이 존재해야한다. Loss가 똑같이 떨어져도 Human performance와 비슷한 것과 큰 차이가 나는 두 상황을 생각해본다면 베이스라인의 중요도를 깨달을 수 있다.
간단한 룰로도 베이스라인을 만들 수 있지만, Human baseline도 굉장히 유용함을 생각해두자. 전문가를 통해 만든 베이스라인은 얻기 어려운 데이터이지만 모델 평가시에 굉장히 유용할 것이다.