GPT 리뷰
Transformer 관련을 찾아보면서 Huggingface의 transformers 레포지토리에 BERT 다음으로 나오는 OpenAI의 GPT를 읽어보기로 헀다. 대신 정리가 너무 오래 걸리는 결과 같은 건 다 제외한다.
Abstract
대규모의 unlabeled 말뭉치가 많지만, 특정 태스크 학습을 위한 labeled data는 엄청 적다. 그래서 이런 데이터로 특정 태스크들을 잘 동작하게 만드는 것이 어렵다. 그래서 OpenAI에서 만든 것이 Generative Pre-Training(GPT)이다. pretrain을 unlabeled 말뭉치에서 진행하고 그 뒤에 특정 태스크들로 fine tuning 시킨다.
1. Introduction
NLP 태스크들의 성능을 위해 word embedding을 쓰는 것처럼 unsupervised 환경에서 좋은 representation을 학습한다면 굉장히 많은 태스크들에서 좋은 성능을 낼 수 있다. 하지만, word-level보다 더 높은 수준의 정보를 unlabeled text로부터 얻어내는 것은 굉장히 어려운 일인데, 그 이유는, 첫번째로 optimization objective가 불명확하고 두번째로 학습한 representation을 target task로 어떻게 사용하는지 또한 불명확하다는 것이다. 이런 불명확함이 semi-supervised learning을 어렵게 만든다.
그래서 이 논문에서는 NLU 태스크를 위한 semi-supervised approach를 소개한다. 목표는 조금만 바꾸어도 다양한 태스크에 적용 가능한 universal representation을 학습하는 것이다. 그래서 이 논문에서 소개하는 모델은 unsupervised pretraining과 supervised fine-tuning 두 단계를 거친다. 첫번째로 unsupervised pre-training 단계는 unlabeled data로부터 LM Objective를 사용하여 학습한다. 그 다음으로 fine-tuning 단계에서 pre-training 단계의 weight들을 적절하게 해당 태스크에 맞도록 바꾼다.
여기서는 역시 Transformer를 사용했고, 그 이유는 structureed memory를 제공하기 때문에 long-term dependencies를 조금 더 잘 다룰 수 있다고 한다. 모델의 검증은 이런 태스크들을 통해서 했다고 한다 - natural language inference, question answering, semantic similarity, text classification.
2. Related Work
Semi-supervised learning for NLP: 예전에는 word-level만 semi-supervised로 잡아냈다면(word-embedding처럼) 요즘에는 unlabeled data로 그 이상으로 잡아내려고 한다.
Unsupervised pre-training: 여러 연구들이 pre-training이 regularization scheme처럼 동작하지만, deep neural network에서는 더 좋은 generalization 성능을 보인다고 한다.
3. Framework
첫번째 단계는 large corpus에서 LM을 학습하고, 그 다음으로 fine tuning을 진행한다.
3.1. Unsupervised pre-training
이 논문에서 소개하는 모델은 Language Modeling을 위해 multi-layer Transformer Decoder를 사용한다. input context token들에 multi-head self-attention에 넣고 나서 position wise feedforward layer에 넣고 target token의 distribution을 낸다.
\[h_0 = UW_e + W_p\] \[h_l = \text{transformer_block} (h_{h-1}) \forall i \in [1, n]\] \[P(u) = \text{softmax}(h_nW_e^T)\]- \(U\)는 input context token
- \(W_e\)는 token embedding matrix
- \(W_p\)는 positional embedding
- \(n\)는 layer 개수
LM은 standard LM을 사용했다. 여기서 \(\mathcal U\)는 unsupervised corpus of tokens.
\[L_1(\mathcal U) = \sum_i \log P(u_i\rvert u_{i-k}, ..., u_{i-1}; \theta )\]3.2. Supervised fine-tuning
학습한 LM 모델의 final transformer block 결과값에 linear output layer를 붙여서 특정 값을 예측할 수 있다.
\[P(y \rvert x^1, ...,, x^m) = \text{softmax}(h^m_l W_y)\]OpenAI팀이 연구한 것에 따르면, 이렇게 사용하는 것은 generalization을 좋게 하는 효과와 convergence를 빠르게 하는 효과가 있다고 한다.
3.3. Task-specific input transformations
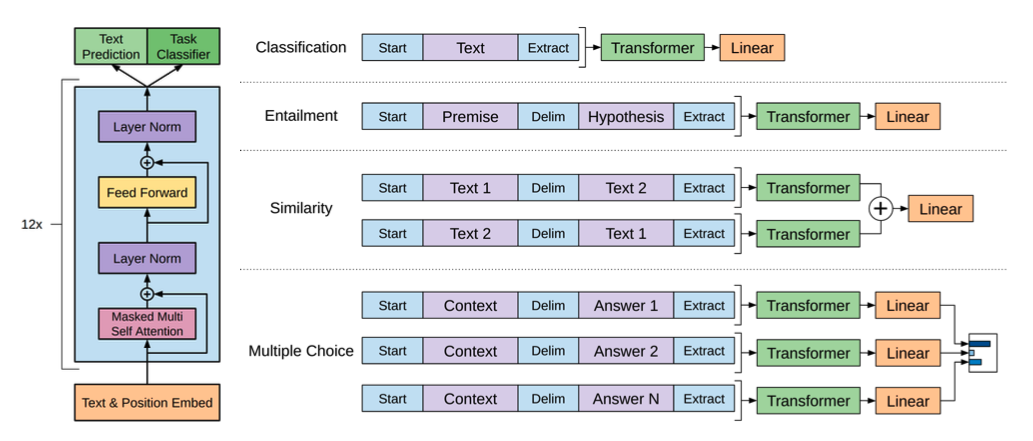
text classification같은 특정 태스크들의 경우에는 위 그림처럼 바로 fine-tuning할 수 있다. 하지만 QA나 textual entailment 같은 경우는 ordered sentence pair, triplet of document, question, and answer 같은 structured input이 들어오게 되는데 이것은 contiguous한 text에서 학습한 pretraining 모델과 불일치가 생기게 된다. 그래서 이럴 때 pre-trained 모델을 잘 쓸 수 있도록 ordered sequence로 바꾸어 주었다고 한다. 이런 걸 traversal style approach라 적어놓았는데, 뭔지는 살펴봐야겠다.
위에서 나온 내용에서 각주로 달려있던 논문 리스트
- R. Collobert and J. Weston. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th international conference on Machine learning, pages 160–167. ACM, 2008.
- T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems, pages 3111–3119, 2013.
- J. Pennington, R. Socher, and C. Manning. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 1532–1543, 2014.
- P. J. Liu, M. Saleh, E. Pot, B. Goodrich, R. Sepassi, L. Kaiser, and N. Shazeer. Generating wikipedia by summarizing long sequences. ICLR, 2018.
- M. Rei. Semi-supervised multitask learning for sequence labeling. ACL, 2017.
- M. E. Peters, W. Ammar, C. Bhagavatula, and R. Power. Semi-supervised sequence tagging with bidirec- tional language models. ACL, 2017.
- T. Rocktäschel, E. Grefenstette, K. M. Hermann, T. Kocˇisky`, and P. Blunsom. Reasoning about entailment with neural attention. arXiv preprint arXiv:1509.06664, 2015.
이 중에 몇개나 볼까..?