한국어 띄어쓰기 모델 작성하기
최근 lovit/namuwikitext를 보면서 데이터를 크게 만지지 않고 할 수 있는 것이 무엇이 있을까 싶었다. 고민해보다 kakao/khaiii의 위키 페이지 중 띄어쓰기 오류에 강건한 모델을 위한 실험을 보면서 띄어쓰기 모델을 만들 수 있겠다 싶어 만들어보았다.
먼저 결과를 정리해보자면, 다른 오픈소스 라이브러리들과 다르게 띄어쓰기 추가/삭제 두가지에 대한 수정이 가능한 모델이 나왔고, 학습 데이터와 비슷한 도메인에서는 0.95 이상의 Accuracy로 수정이 가능했다. 또한 MBP 2020년형에서 128 batch size, 128 sequence length 설정에서 0.1ms/sentence 내의 속도로 띄어쓰기 정제가 가능했다. 모델 사이즈는 그래프를 포함하여 1.5MB 정도의 사이즈로 만들었다. 이 포스트에서 설명하는 코드의 레포지토리는 jeongukjae/korean-spacing-model이고 라이브 데모는 https://jeongukjae.github.io/korean-spacing-model/에서 볼 수 있다.
먼저 사용가능한 오픈소스 띄어쓰기 모델 찾기
khaiii를 보고 만들 생각하긴 했지만, 실제로는 POS 태깅을 위한 라이브러리이기 때문에 기타 사용가능한 라이브러리를 찾아보았다.
- Python으로 작성된 lovit/soyspacing이 가장 쉽게 사용가능한 라이브러리였고, 휴리스틱 기반의 알고리즘을 사용한다. 붙여써야 하는 띄어쓰기를 띄어쓰는 경우는 잘 없다는 전제 하에 개발하였다고 한다. 즉, 이 문자 다음에 띄어쓰기를 해야하는지 말아야 하는지에 대해 binary classification문제로 생각하였다고 한다. classification은 학습 코퍼스에 대한 빈도를 세어 해결한다. 빈도만을 세는 만큼 학습속도가 빠르지만, 모델 파일이 크고 추론 시에도 하이퍼파라미터를 수정해가면서 사용해야 한다.
- 또 haven-jeon/KoSpacing이 있었고 R, Python로 작성된 라이브러리이며, CNN - BatchNorm - FFN - GRU - FFN의 구조였다. 충분히 무거운 모델이라고 판단했다.
- 그 외에는 pingpong-ai/chatspace가 있다. 이 라이브러리는 딥러닝 모델을 사용하였으며, 대화체 데이터로 학습했다. 하지만 CNN - BatchNorm - FFN - BiLSTM - LayerNorm - FFN 구조이고 KoSpacing의 구조 중 GRU에서 LSTM으로 바뀐 모델이다. (
사랑해요 핑퐁팀) - 또 warnikchow/raws [Real-time Automatic Word Segmentation]라는 라이브러리는 CNN, LSTM Feature를 Concat하여서 분류하는 모델이다. 이 모델도 문자 뒤의 띄어쓰기를 분류하는 모델이다.
접근법
다음 목적이 이 모델을 만든 주 목적 혹은 제한사항이다. 1) 이 모델의 목적은 전처리가 가장 크기 때문에 때문에 빠른 속도와 작은 모델 사이즈는 필수이다. 빠른 속도라고 함은 문장 당 1ms를 정했고, 모델 사이즈는 FP32 기준으로 5MB를 정해놓았다. 2) 띄어쓰기 수정은 “빠진 띄어쓰기 추가”, “과한 띄어쓰기 삭제” 두가지로 정한다. 따라서 binary classification이 아닌 multiclass classification으로 정했고, 문자의 연속이 들어올 때 각 문자별로 0, 1, 2를 분류하는 모델을 만든다. 3) 타겟 도메인에 해당하는 텍스트로 학습시킬 경우 충분히 사용가능한 성능이 나와야 한다.
모델 구조
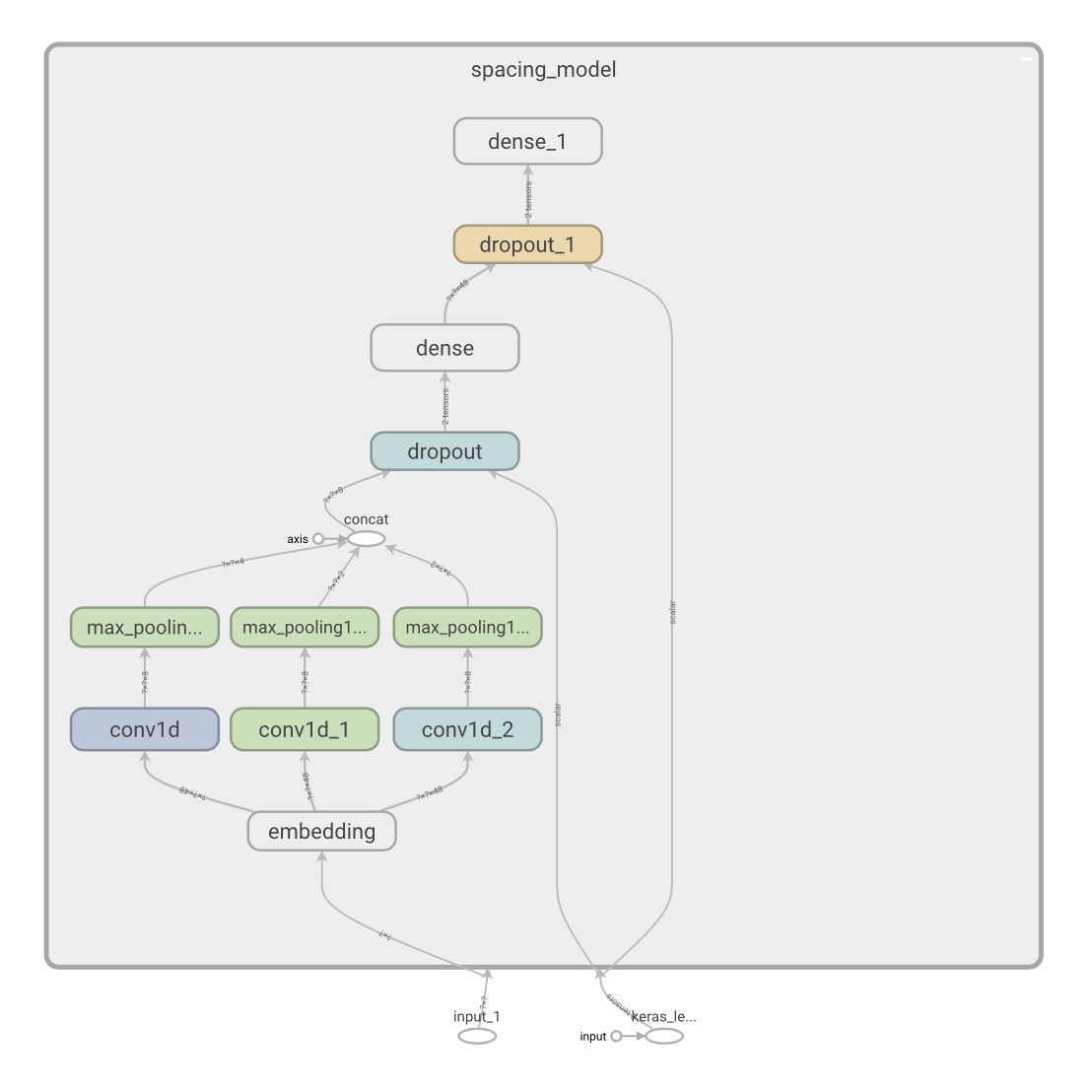
Bi-LSTM 구조를 CNN구조로 교체하면 뒤지지 않는 성능을 얻으면서 훨씬 빠른 모델을 얻을 수 있다.(Strubell et al., 2017) 이 때문에 CNN구조를 메인으로 채택하였으며 그 뒤로는 단순히 분류를 하기 위해 FFN을 두개 이어서 놓았다. CRF를 사용하지 않은 이유는 Viterbi 디코딩을 하는 것에 연산이 많이 소요되기 때문이다. 실제 Conv1D 레이어의 개수는 설정에 따라 달라질 수 있다. 구성을 하고보니 khaiii와 비슷한 모델이 되었다.
학습 방법
학습은 일반적인 한국어 문장만으로 구성된 데이터셋에서 Self supervised learning으로 수행한다. 각 텍스트 파일을 읽어 BOS, EOS 태그(<s>, </s>)를 붙인 뒤 문장의 띄어쓰기를 랜덤하게 삭제/추가한다. 또 그를 원래의 문장으로 복구하기 위한 레이블을 만든다.
| 종류 | 내용 |
|---|---|
| 원래 문장 | 한국어 띄어쓰기 |
| 학습할 문장(예시) | <s>한 국어띄어 쓰기</s> |
| 학습할 레이블(예시) | [0, 0, 2, 0, 1, 0, 0, 2, 0, 0, 0] |
레이블은 0이 현재 텍스트 유지, 1이 현재 문자 뒤 공백 문자 추가, 2가 현재 공백 문자 삭제 의미를 지닌다.
학습 데이터
실제로 사용하기 위해서는 물론 타겟도메인에 해당하는 코퍼스에서 학습시켜야 하겠지만, 일반적으로 사용이 가능하냐를 보기 위해 나무위키 텍스트(lovit/namuwikitext)에서 실험해보았다. Tag v0.2를 사용했고, train 코퍼스를 기준으로 학습하였다. 나무위키 텍스트의 패턴은 어느정도 맞는 맞춤법이라 보고 특별한 정제를 하지 않았다. 정확한 띄어쓰기를 맞추기보다 어느정도 괜찮은 띄어쓰기를 해주는 모델을 만들고 싶었고 무엇보다 일일히 수정해주기가 싫었다.. ㅠㅠ
Vocab 구성 방법
학습 코퍼스 내부의 모든 문자의 출현 빈도를 센 뒤 padding, bos, eos, unk를 포함하여 상위 5000개로 잘랐다. 이 때 나무위키텍스트에 대해서는 character coverage가 0.9996이 넘는다.
결과
아래는 나무위키텍스트 50만 문장으로 학습시킨 모델의 결과이다. sequence length를 128으로 batch size를 64로 설정했다. 또한 learning rate를 1e-2으로, 또 Optimzier는 Adam Optimizer를 사용하였다. 모델은 hidden size 48로 학습시켰으며 vocoab은 5000개로 구성했다. 그림에는 conv1d가 3개있지만, 실제 학습을 위한 conv1d 커널 크기는 2 ~ 10까지 여러개로 구성했다. 0.5의 확률로 공백을 삭제했고, 0.15확률로 공백을 무작위로 추가했다. 하이퍼 파라미터 튜닝은 없었고, learning rate만 어느정도 잘 잡도록 조정해놓았다. 아무래도 공백을 없는 문장에서 추가하는 경우가 많을테니 공백 삭제 비율을 훨씬 높게 주었다.
모델 성능
나무위키 테스트 코퍼스에 대해 테스트해본 모델 성능은 아래와 같다. 셔플한 뒤 랜덤하게 약 10,000 문장에 대해 측정했다. (sequence length 128) Accuracy는 padding을 제외하고 실제 의미있는 문자의 분류만을 세었다. (BOS ~ EOS)
| 공백 삭제 비율 | 공백 추가 비율 | accuracy | |
|---|---|---|---|
| 0.0 | 0.0 | 0.9828 | 레이블은 전체 0 |
| 0.3 | 0.0 | 0.9730 | |
| 0.5 | 0.0 | 0.9662 | |
| 0.8 | 0.0 | 0.9535 | |
| 1.0 | 0.0 | 0.9442 | 공백 전체 삭제 |
| 0.5 | 0.15 | 0.9597 | 학습 설정 |
| 0.0 | 0.5 | 0.9666 | |
| 0.0 | 1.0 | 0.9539 | 공백 전체 추가 |
아무래도 공백 추가할 곳을 많이 찾도록 학습하였기 때문에 공백 추가에 대해서 더 잘해내는 모습을 보였다.
모델 속도
MacBook Pro (13-inch, 2020, Four Thunderbolt 3 ports) (2 GHz Quad-Core Intel Core i5)에서 batch size 128, sequence length 128로 CPU 추론을 돌릴 시 배치당 약 11.31ms, 한 문장당 약 0.088 ms 정도 소요된다. 동일한 설정으로 batch size만 1로 설정할 경우, 한 문장당 약 0.518ms가 소요된다.
결론
토이 프로젝트로 띄어쓰기 모델을 만들어보았는데 생각보다 괜찮은 성능을 보이지만, 개선이 많이 필요해보인다. 모델 크기에 관한 개선보다 1) 실제 labeling하는 컴포넌트 변경 (FFN) 2) 학습 하이퍼파라미터 조정 정도가 가장 먼저 필요해 보인다. 또한 필요하다면 사용자 사전 기능을 추가하여 사용자 사전에 존재할 경우 중간에서 띄어쓰지 않는 기능을 추가할 수 있어보인다. 추가로 나무위키 데이터에서 학습을 시켰을 때 나무위키 데이터 내에서는 어느정도 띄어쓰기를 잘 하지만, 구어체에서는 띄어쓰기를 잘 해내지 못한다. 이로 보아 구어체 데이터를 잘 활용한다면 구어체에서도 사용이 가능해보인다.
레이블링하는 컴포넌트 변경은 속도를 조금 포기하면서 CRF 혹은 최근 EMNLP 2020에 나온 AIN도 활용하는 것이 가능해보인다.
추가로 이 글의 첫 두문단의 띄어쓰기를 모두 제외한 뒤 이 띄어쓰기 모델로 띄어쓰기를 해보았다. 아래는 그 결과이다.

최근 lovit/namu wikitext를 보면서 데이터를 크게 만지지 않고 할 수 있는 것이 무엇이 있을까싶었다. 고민해보다 kakao/khaiii의 위키페이지중 띄어쓰기 오류에 강건한 모델을 위한 실험을 보면서 띄어쓰기 모델을 만들 수 있겠다 싶어 만들어보았다.
먼저 결과를 정리해보자면, 다른 오픈소스라이브러리들과 다르게 띄어쓰기 추가/삭제두 가지에 대한 수정이 가능한 모델이 나왔고, 학습 데이터와 비슷한 도메인에서는 0.95 이상의 Accuracy로 수정이 가능했다. 또한 MBP 2020년형에서 128 batch size, 128sequencelength 설정에서 0.1ms/sentence 내의 속도로 띄어쓰기 정제가 가능했다. 이포스트에서 설명하는 코드의 레포지토리는 jeongukjae/korean-spacing-model이고 라이브 데모는 https: //jeongukjae. github. io/korean-spacing-model/에서 볼 수 있다.
띄어쓰기 되어야 할 곳에서 제대로 되지 않는 몇몇 지점이 있지만, 이 정도라면 충분히 합리적인 모델이라고 생각한다. 모든 글자를 다 띄어쓴다면 어떻게 될지 궁금하여 아래의 텍스트도 넣어보았다.

이 부분은 많이 못한다.. 적당히 수동으로 문장을 변형시켜 넣어보면 어떻게 될까? 아래 문장만 넣어놓았다.
입력: 최근 lovit/namuwikitext를보면서 데이터를 크게만지지않고 할수있는것이 무엇이있을까 싶었다. 고민해 보다kakao/khaiii의 위키페이지중 띄어쓰기오류에 강건한 모델을 위한 실험을 보면서 띄어쓰기모델을 만들수있겠다싶어 만들어보았다.
최근 lovit/namu wikitext를 보면서 데이터를 크게 만지지 않고 할 수 있는 것이 무엇이 있을까 싶었다. 고민해보다 kakao/khaiii의 위키페이지중 띄어쓰기 오류에 강건한 모델을 위한 실험을 보면서 띄어쓰기 모델을 만들 수 있겠다 싶어 만들어보았다.
이런 부분은 좀 괜찮게한다.
끝!
참고자료
- GitHub: lovit/namuwikitext
- GitHub: lovit/soyspacing
- GitHub: haven-jeon/KoSpacing
- GitHub: pingpong-ai/chatspace
- GitHub: warnikchow/raws
- 핑퐁 블로그 - 대화체에 유연한 띄어쓰기 모델 만들기
- Emma Strubell, Patrick Verga, David Belanger, and Andrew McCallum. 2017. Fast and accurate entity recognition with iterated dilated convolutions. arXiv:1702.02098.
- Xinyu Wang el al., 2020. AIN: Fast and Accurate Sequence Labeling with Approximate Inference Network. arXiv:2009.08229.