Revealing the Dark Secrets of BERT 리뷰
GLUE 태스크와 그 subset을 이용하여 정량적, 정성적으로 BERT heads 분석한 논문이다. EMNLP 2019에 Accept된 논문.
Main Contribution:
- analysis of BERT’s capacity to capture different kinds of linguistic information by encoding it in its self-attention weights.
- present evidence of BERT’s over- parametrization & suggest simple way of im- proving its performance.
Methodology
아래 세개의 Research Questions에 대해 집중함
- What are the common attention patterns, how do they change during fine-tuning, and how does that impact the performance on a given task?
- What linguistic knowledge is encoded in self-attention weights of the fine-tuned models and what portion of it comes from the pre- trained BERT?
- How different are the self-attention patterns of different heads, and how important are they for a given task?
실험 환경은 아래와 같음
- huggingface/pytorch-pretrained-bert 사용하고, BERT base uncased 사용.
- 사용한 GLUE tasks: MRPC, STS-B, SST-2, QQP, RTE, QNLI, MNLI
- Winograd는 데이터셋 사이즈 때문에 제외했고, CoLA는 GLUE 신버전에서 제외되기 때문에 사용하지 않았다.
- fine-tuning hyperparam은 BERT 원 논문을 따라감
Experiments
Bert’s self-attention patterns

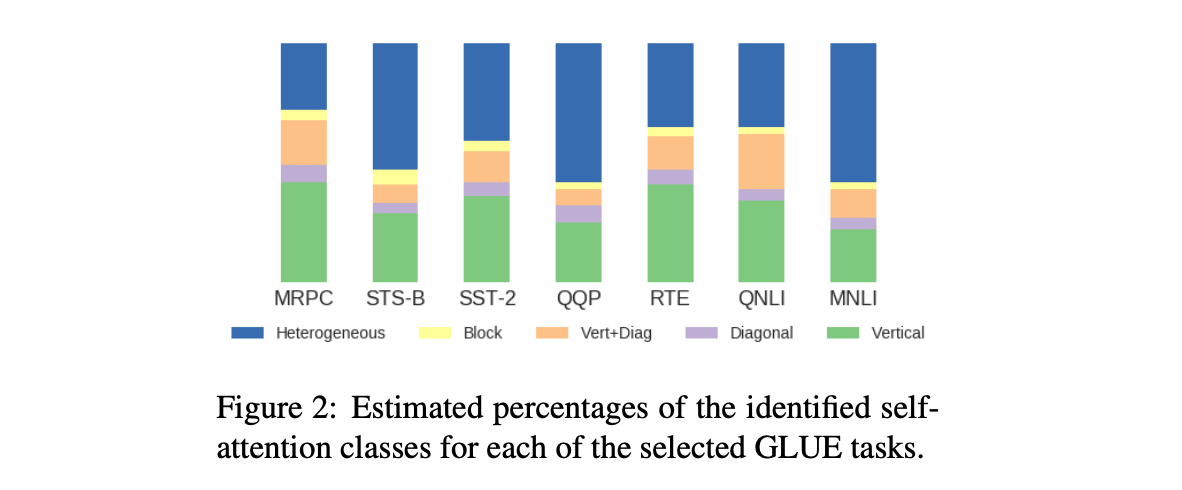
- BERT의 Self attention pattern을 뽑으면 위와 같은 패턴들이 있음
- Vertical:
[CLS],[SEP]같은 토큰에 Attention이 걸리는 것. - Diagonal: previous, following tokens에 Attention
- Vertical + Diagonal
- Block: Intra-sentence attention
- Heterogeneous
- Vertical:
- Heterogeneous는 32% ~ 61%까지 다양하지만 전체적으로 많았다.
- 그래서 Heterogeneous attention이 잠재적으로 구조적인 정보를 잡아낼 수 있다고 판단.
Relation specific heads in BERT
Baker et al., 1998 의 내용을 잡아낼 수 있는지 테스트. 조건을 좀 많이 검.
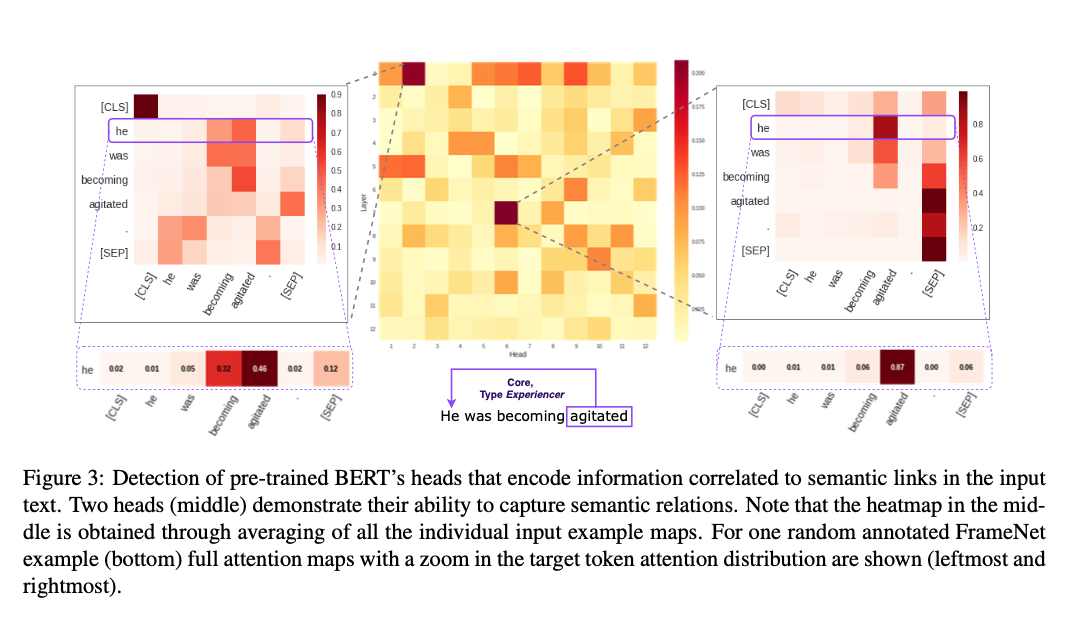
- 위와 같은 예시를 많이 볼 수 있었고, 이게 어느정도의 증거를 제시해준다고 해석함
- 조금 더 일반적인 상황에 대한 증명은 future works.
Change in self-attention patterns after fine-tuning
fine tuning 전 후의 head별 Attention weight를 뽑아서 cosine similarity를 구해봄.
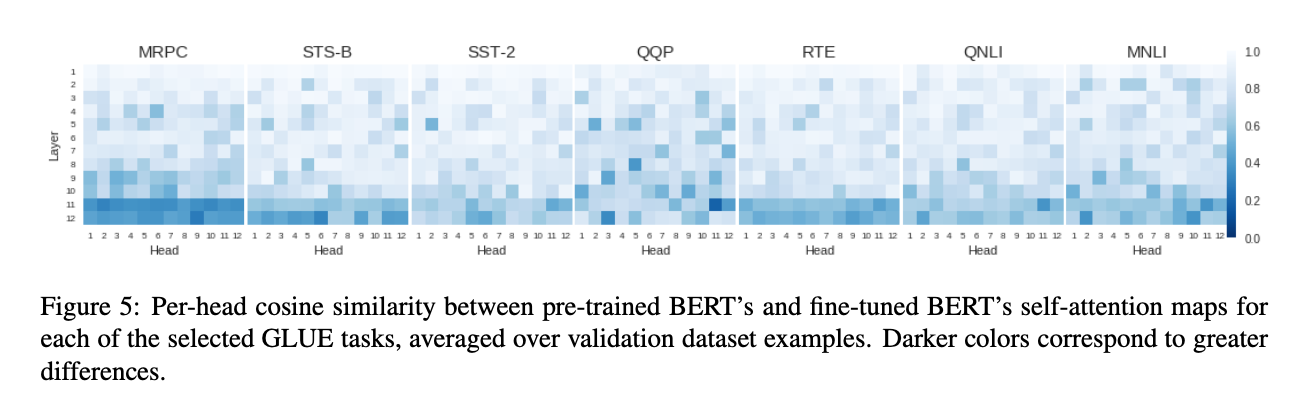
QQP를 제외하고는 마지막 2레이어가 많이 바뀌는 것을 볼 수 있다.
Attention to linguistic features
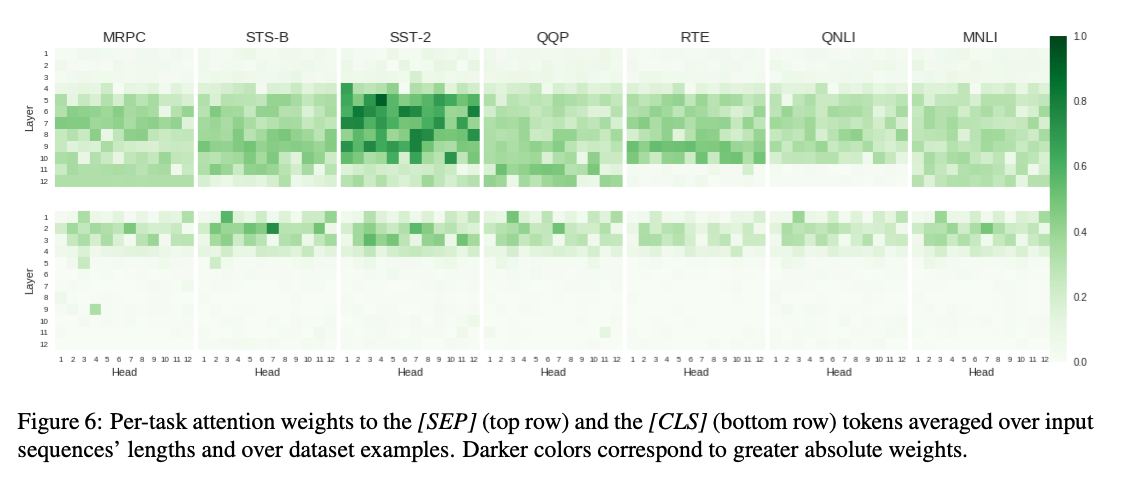
- CLS는 앞쪽 레이어만 Attention이 많이 들어가더라.
- 그 뒤부터는 SEP에 Attention 걸리는 것이 지배적이다.
- SST-2는 SEP 토큰이 하나들어가니까 (입력 문장이 하나니까) 유난히 큰 값을 가지는 것으로 보인다.
- 이런 경향을 보니까 task specific하게 linguistic reasoning을 배우는 것보다 pretrained BERT로부터 오는 것 같다.
Token to token attention
패스
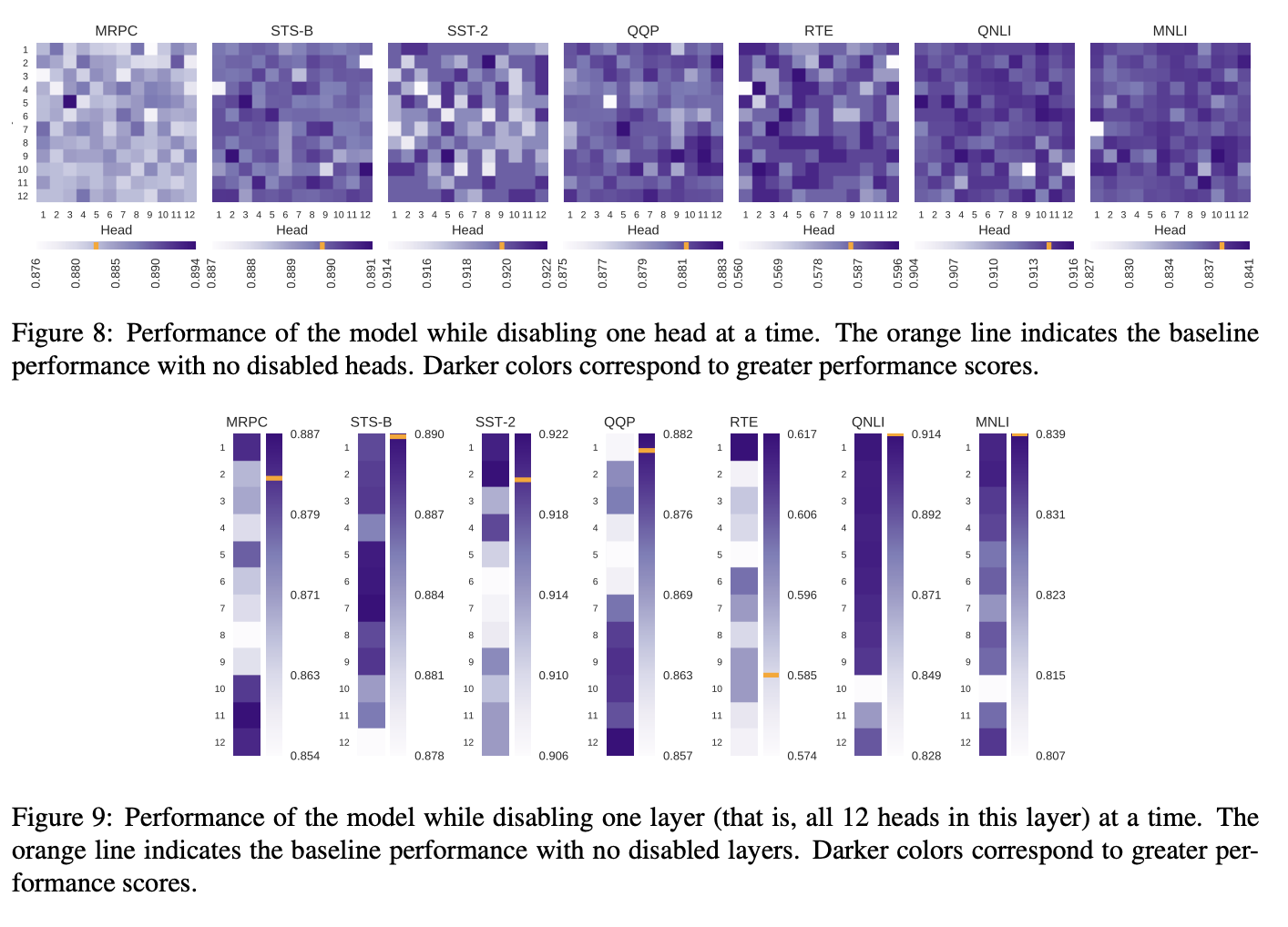
Disabling self attention heads
이미 related works 섹션에서 self attention heads 마스킹하는 논문을 레퍼런스로 걸어놓음
- 역시 잘 되고 오르기도 함
- 레이어 자체를 드랍해도 잘 됨
Discussion
base여도 over parameterize가 잘 됨
BERT의 over parameterization을 다각도로 보여준 논문인 듯 하다. 몇몇 분석은 "...?"한 것도 있지만, “이렇게 해라!”라는 논문보다는 “이렇더라”라는 논문이라 재밌게 읽었다. 경량화시에 참고할 만한 논문.
July 6, 2020
Tags:
paper