SimCSE 리뷰 & KR-BERT 이용해서 구현해보기
얼마전에 GitHub explore reposistories 탭에서 SimCSE라는 레포지토리를 발견해서 논문을 간단하게 보았다. Contrastive Learning 할 때 다른 dropout을 적용한 자신을 positive pair로, 배치 내부의 다른 인스턴스를 negative pair로 사용하는 방법인데, “이게 정말 될까?” 싶어 한국어로 시도해봤다.
_
- 논문 링크: https://arxiv.org/abs/2104.08821
- 오피셜 레포지토리 링크: https://github.com/princeton-nlp/SimCSE
- KR BERT로 구현한 SimCSE 링크: https://github.com/jeongukjae/KR-BERT-SimCSE
논문 내용
제일 놀랄만한 내용은 Unsupervised 학습만으로도 NLI 데이터로 미리 학습한 Sentence RoBERTa 성능이 나온다는 점이었다. 또한 SimCSE 방법으로 NLI 데이터도 추가학습하면 물론 NLI 데이터로 학습한 Sentnece RoBERTa도 꽤 큰 차이로 앞지른다.
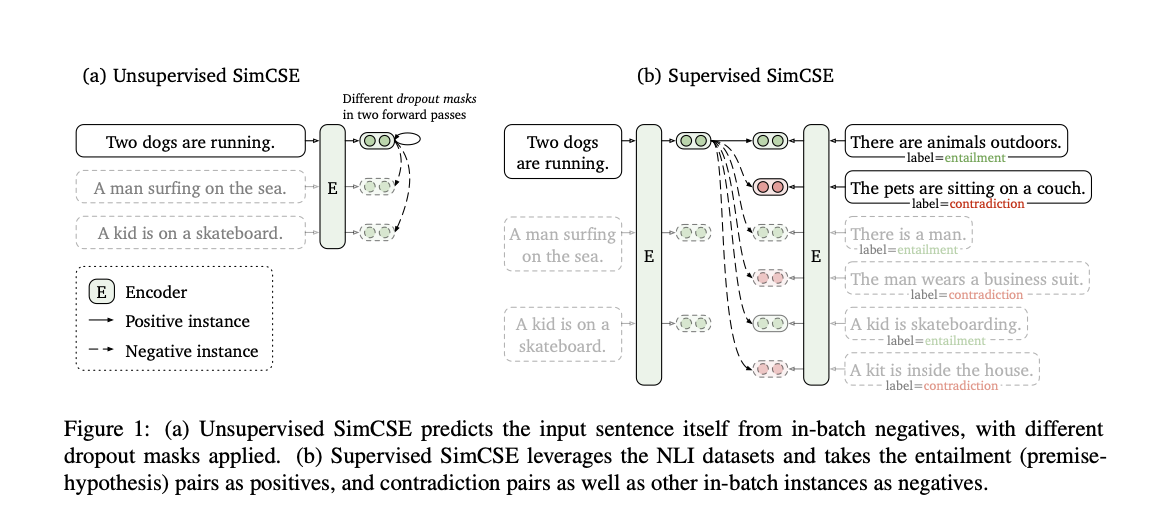
방법은 위 이미지 한장으로 전부 설명된다. Unsupervised 방식은 문장을 두번 forward해서 같은 문장으로부터 나온 representation을 positive pair로 사용하고 같은 배치내의 다른 표현값들을 negative pair로 사용한다. (참고 이슈) 서로 다른 dropout mask로 data augmentation을 한다고 생각하면 된다.
Supervised 방식은 NLI 데이터셋에서 entailment를 positive pair로, contradiction + in-batch negative를 negative pair로 활용한다. STS Benchmark로 성능을 측정하니 진정한 의미에서 Supervised는 아닌 것 같기도 하고..
이 논문에서 말하는 SentenceBERT의 supervised 버전도 STS 데이터셋에 학습시킨 버전이 아닌 NLI까지만 학습시킨 버전이다.
Unsupervised
언뜻 생각했을 때는 잘 안될 것 같은데, https://arxiv.org/abs/2005.10242 논문을 말하면서 이렇게 설명한다. (자세한 수식은 논문 참고해주세요)
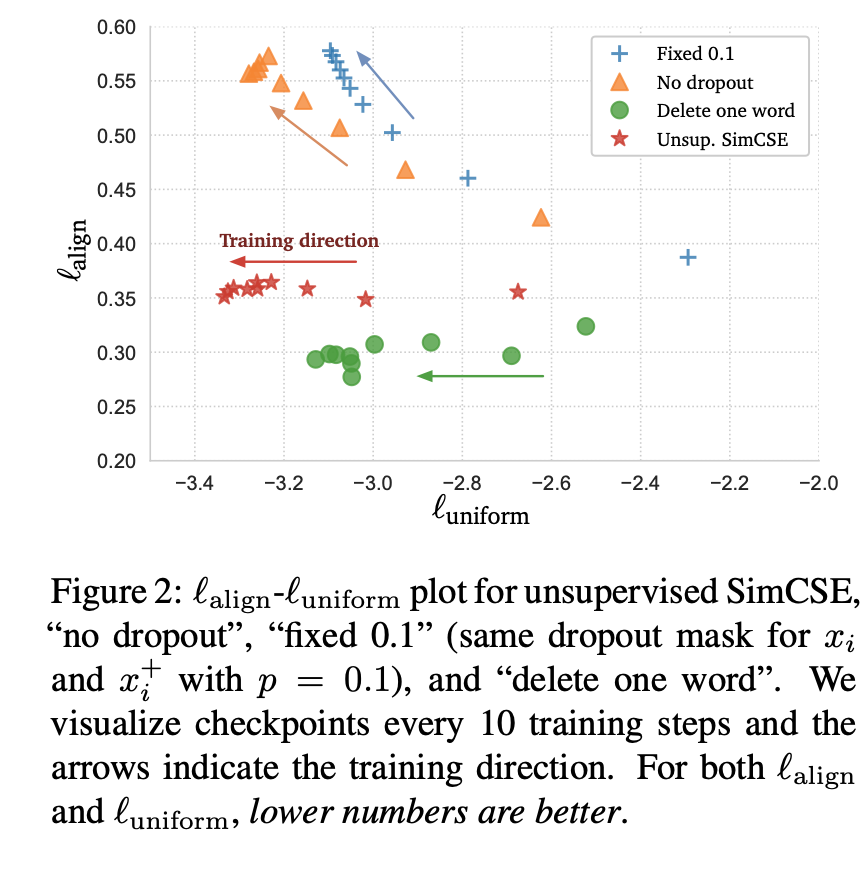
contrastive learning은 두가지 중요한 점이 있는데, alignment와 uniformity이다. positive pair끼리의 expected distance를 계산하는 것이 alignment이고, 전체 데이터셋에 대해 얼마나 임베딩이 균일하게 분포하는지 측정하는 것이 uniformity이다. (둘다 수식상 낮아야 좋은 값이다)
여기서 fixed 0.1(한 문장을 동일한 dropout에 대해 두번 forward하는 방법)이나 no dropout은 alignment가 증가하는 추세를 보인다. 하지만 SimCSE의 방법을 사용할 때는 alignment의 증가는 잘 억제하면서 uniformity를 잘 향상시킬 수 있다고 한다.
이걸 보고 delete one word 방식을 쓰면 안되나했는데, 학습은 잘 되지만, 성능이 좋지는 않다고.. 또한 결국에는 uniformity가 SimCSE보다 덜 향상된다고 한다.
Supervised
snli, mnli를 사용했고, Unsupervised SimCSE의 내용에서 positive pair를 entailment 문장으로 치환하고 contradiction을 negative pair로 추가만 했다.
학습 세팅하기
개인적으로 KR-BERT를 사용하기에 제일 편해서 KR-BERT를 기본 모델로 잡고 시작해봤다. 그리고 KLUE가 KR-BERT character 모델을 사용했길래 subchar가 아닌 char 모델로 사용했다. (subchar는 자소 단위까지 tokenize하는 모델이다)
다만 KLUE STS는 벤치마크 데이터셋을 제시하는 논문이니 단순한 방식으로 파인튜닝을 해본 것에 대한 성능이고 cross encoding 방식에 STS 데이터셋을 직접 사용해서 좋은 비교 대상은 안되었다.
학습 데이터로는 snli, mnli 번역 데이터셋인 KorNLI를 위주로 사용했고, unsupervised 학습은 얼마전애 만들어둔 위키피디아 덤프를 문장단위로 쪼개놓은 데이터셋을 사용했다. 학습 데이터 불러오는 것도 예전에 만들어둔 tfds-korean으로 간단하게 로딩했다.
- unsupervised 학습용으로 사용한 데이터셋: TFDS-Korean - Korean Wikipedia Corpus
- supervised 학습용으로 사용한 데이터셋: TFDS-Korean - KorNLI
성능 측정은 KorSTS, KLUE STS 데이터셋을 사용했고, 테스트셋이 공개되어 있지 않은 KLUE STS의 테스트셋은 사용하지 않았다.
학습 결과
결과 테이블 보러가기 -> 링크
KorSTS devset 성능이 제일 좋은 모델로 측정한 결과이다.
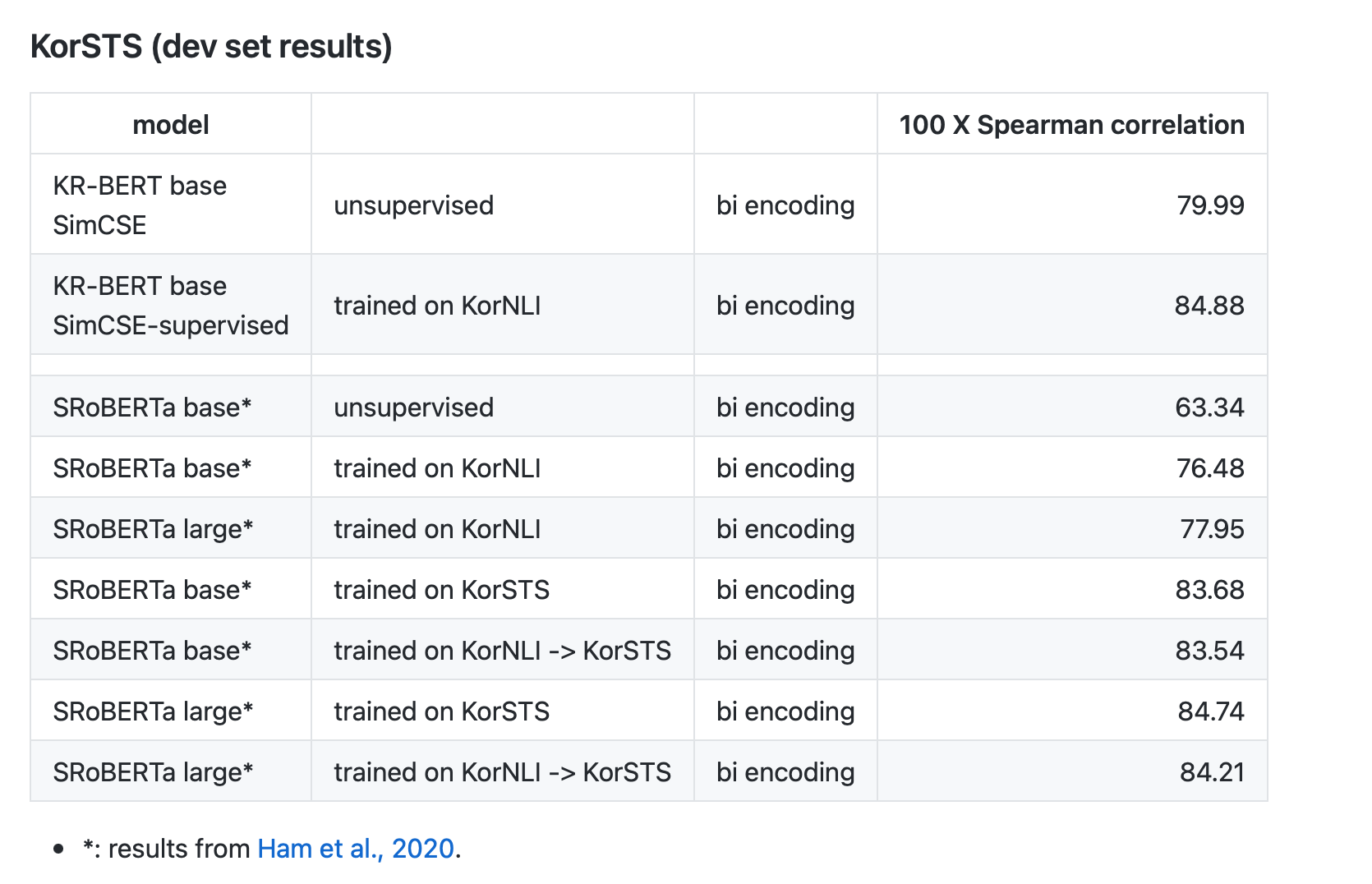
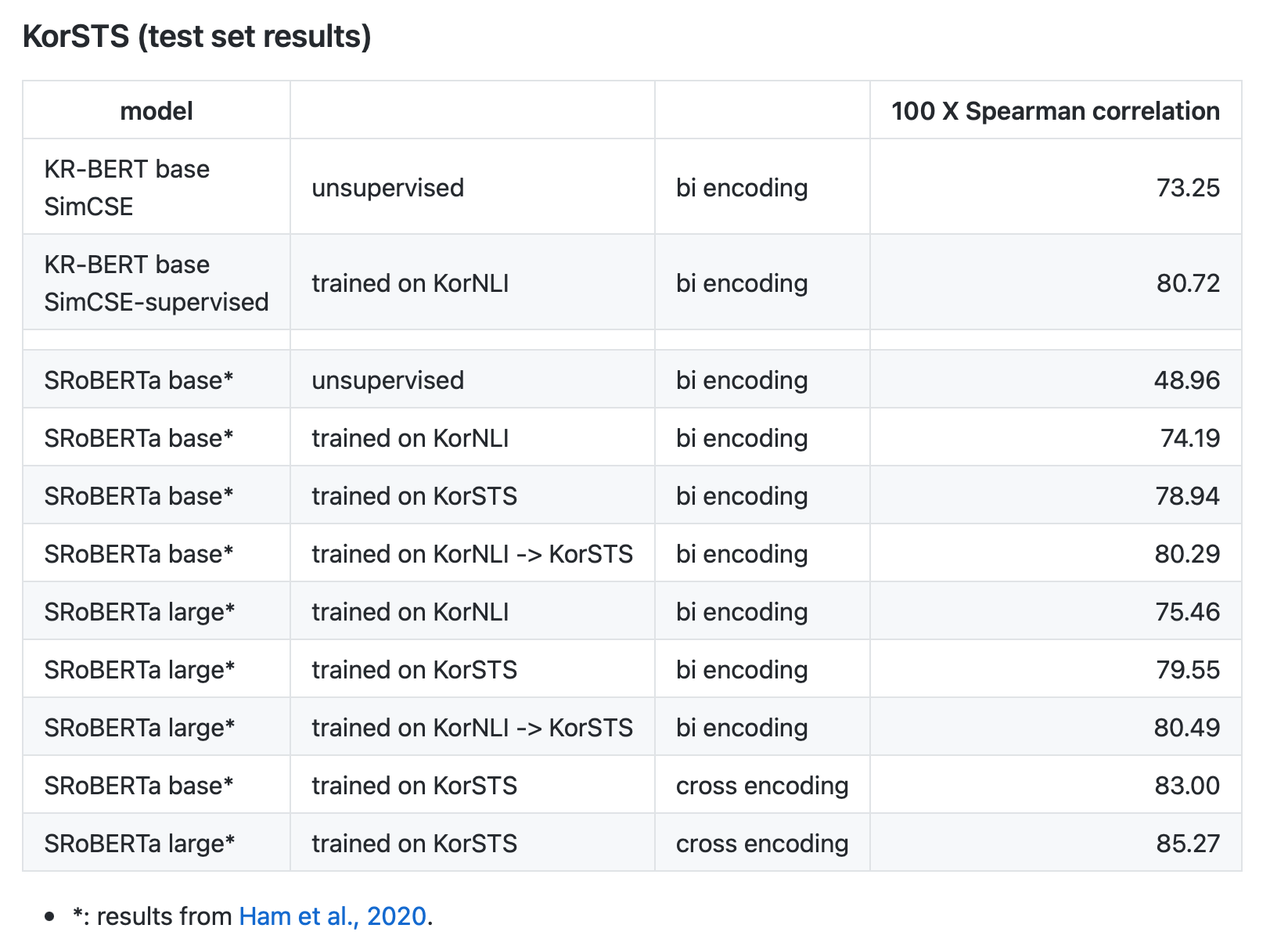
KorSTS 결과로는 꽤 좋게 나왔다. unsupervised는 devset 기준으로 SentenceRoBERTa large 사이즈에 KorNLI를 학습한 모델보다 좋은 결과(+ 2.04)를 보여줬다. 다만 testset 기준으로는 KorNLI에 학습한 RoBERTa들보다 안좋은 모습을 보인다.
KorNLI 데이터셋을 학습한 supervised 모델은 devset, testset 모두 bi encoding 모델들보다 더 좋은 모습을 보여줬다. 심지어 large 모델 성능보다도 좋은 모습을 보여줬다. KorNLI에 대해 학습한 모델들끼리만 비교하면 굉장히 좋은 결과를 보여줬다.
그래도 역시 cross encoding 모델들보다는 안좋은 성능을 보여줬다.
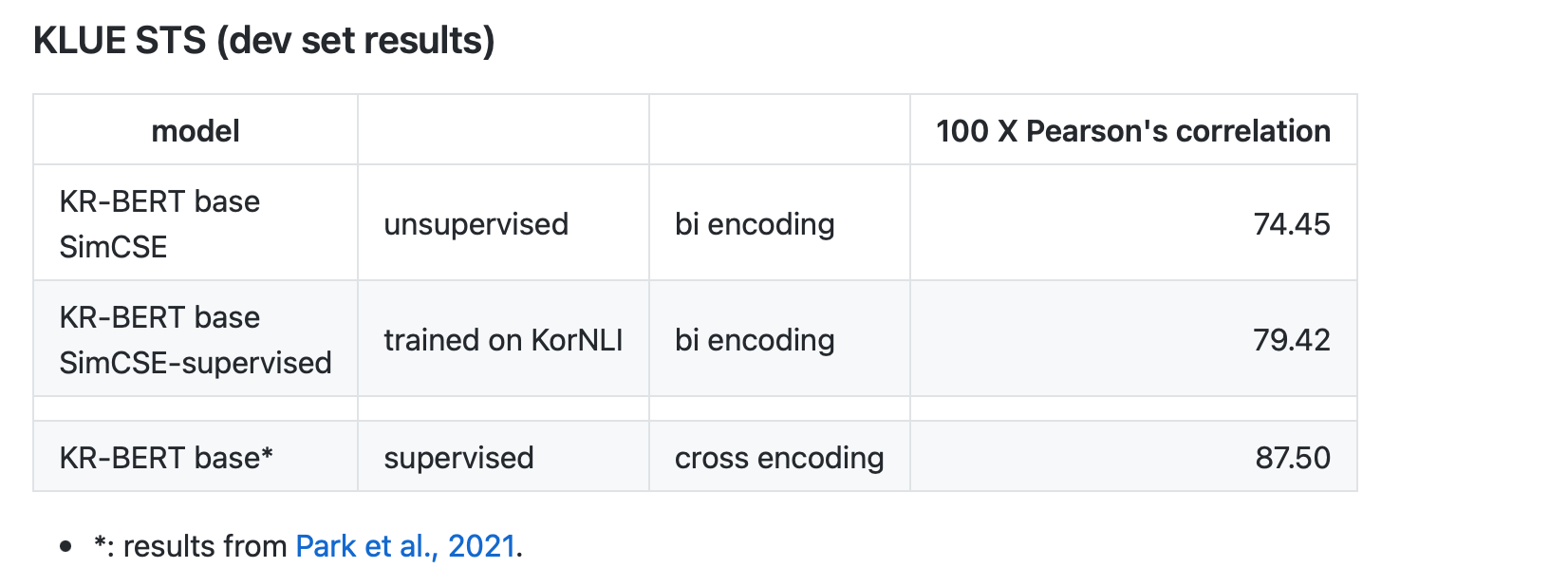
KLUE STS는 성능 비교하기가 조금 그렇긴 하지만.. 있길래 해봤고, 당연히 cross encoding 모델에 비해 성능이 떨어졌다.
문장 몇개 유사도 뽑아보기
KorSTS 테스트셋에서 아래의 문장 10개 뽑아서 서로의 유사도를 측정해봤다. (supervised 모델)
0: 한 소녀가 머리를 스타일링하고 있다.
1: 한 소녀가 머리를 빗고 있다.
2: 한 무리의 남자들이 해변에서 축구를 한다.
3: 한 무리의 소년들이 해변에서 축구를 하고 있다.
4: 한 여성이 다른 여성의 발목을 재고 있다.
5: 한 여자는 다른 여자의 발목을 측정한다.
6: 한 남자가 오이를 자르고 있다.
7: 한 남자가 오이를 자르고 있다.
8: 한 남자가 하프를 연주하고 있다.
9: 한 남자가 키보드를 연주하고 있다.
0 1 2 3 4 5 6 7 8 9
0 1.00 0.84 0.23 0.11 0.53 0.48 0.32 0.32 0.28 0.38
1 0.84 1.00 0.23 0.14 0.57 0.49 0.33 0.33 0.27 0.31
2 0.23 0.23 1.00 0.82 0.15 0.17 0.23 0.23 0.23 0.22
3 0.11 0.14 0.82 1.00 0.12 0.13 0.16 0.16 0.13 0.12
4 0.53 0.57 0.15 0.12 1.00 0.91 0.28 0.28 0.19 0.24
5 0.48 0.49 0.17 0.13 0.91 1.00 0.23 0.23 0.18 0.21
6 0.32 0.33 0.23 0.16 0.28 0.23 1.00 1.00 0.45 0.38
7 0.32 0.33 0.23 0.16 0.28 0.23 1.00 1.00 0.45 0.38
8 0.28 0.27 0.23 0.13 0.19 0.18 0.45 0.45 1.00 0.60
9 0.38 0.31 0.22 0.12 0.24 0.21 0.38 0.38 0.60 1.00
해보고 나서 드는 생각
- KLUE STS에 대해서 Sentence BERT 학습을 추후에 해보고 비교해보면 좋지 않을까?라고 생각하지만, KorNLU 데이터셋에 대해서 이미 SimCSE가 좋은 것 같은데 토이 프로젝트로 하기엔 귀찮다.
- KorSTS 데이터셋을 아예 안 썼는데 논문에 적힌 bi encoding 방식의 SRoBERTa large 모델 성능보다 좋은 성능을 보여주는게 신기하다.
- 추가로 Loss 잘 정의해서 regression task로 KorSTS 데이터셋을 넣어보고 싶은데 그건 추후에 해보자.
- 대략 생각부터 결과 뽑고 이 블로그 포스트 쓰기까지 커밋 로그 보니까 GPU 학습 시간빼고 3일동안 4시간 남짓 걸린 것 같은데 이제서야 진짜 개발 환경에 다 내 손에 편하게 느껴지는구나 싶다.
- Distributed Training을 할 수 있게 작성했는데, 빠르게 테스트해보려고 1 GPU에서만 해봤다. 논문에서는 일정 수준으로 큰 배치를 사용하면 성능이 좋아진다고 적혀있어서 해볼껄 그랬나 싶기도 하고.
- 문장으로 학습 해본 예시지만, 다른 데이터들(image + text처럼 멀티 모달이나 등등)도 가능한 방법으로 보인다.
- pretrain을 적절한 방식으로 해서 일반적인 방법으로 classifier도 학습시켜 쓰고 임베딩 잘 뽑게 SimCSE unsupervised 방법으로도 학습시켜 쓰면 정말 좋을 것 같다. 특히 라이브 데이터가 많아서 레이블링 잘 안하는 회사 같은 곳들에서?
- 원 레포지토리에서는 데모도 만들던데 데모 만들어봐도 괜찮겠다. ainize 같은 걸로 뚝딱🔨해볼까
- Density Plot 같은 거도 그려볼걸 그랬나..