ZeRO: Memory Optimization Towards Training A Trillion Parameter Models 리뷰
매우 큰 모델의 학습 프레임워크로 MegaTron을 뛰어넘는 성능을 보여줘 화제였던 논문이다. arvix 링크는 https://arxiv.org/abs/1910.02054이고, pytorch용 구현은 GitHub - microsoft/DeepSpeed에서 볼 수 있다.
Abstract
- 현재 큰 모델을 학습시키는 방법은 매우 제한되어 있다. 메모리가 낭비되거나 연산이 늦어지는 등의 문제점이 존재한다.
- Data Parallelism은 메모리가 매우 redundant하다.
- Model Prallelism은 communication 비용이 매우 높아 연산 효율이 안좋다.
-
We develop a novel solution, Zero Redundancy Optimizer (ZeRO), to optimize memory, achieving both memory efficiency and scaling efficiency.
1 Extended Introduction
- Model Parallelism을 통해 큰 모델을 학습시키는 것은 굉장히 힘든데, 이렇게 가정해보자
- 1 Trillion Parameter를 가지는 모델을 학습시키면 한 노드에 20B씩 학습이 가능할 때 50노드가 필요하고 DGX-2 노드는 16GPU이니까 800-way parallelism..이 된다.
- 효율적으로 학습시키려면 어떻게 되었든 Memory Redundancy를 잡아야한다.
- 메모리는 대부분 아래와 같은 요인으로 인해 낭비된다.
- optimizer states (Adam Optimizer와 같은 경우에 momentum과 variance)
- gradients
- parameters
- 이 요인들을 OGP라 통칭
- 그래서 ZeRO는 위 세개를 전부 다 나눠버렸다.
- Optimization Stage를 세개로 가져감
- Partitioning Optimizer States
- Partitioning Graidents
- Partitioning Parameters
- ZeRO에서 Optimizer States만 최적화한 것을 ZeRO-OS라고 부른다.
- 결과적으로
- ZeRO-OS에서 학습하는 모델은 6B 정도는 V100에서 학습가능하게 만들었다. (기존에는 1.5B 정도가 한계)
- Model Parallelism과 같이 100B정도까지 학습가능해진다. MegaTron은 20B정도 가능하다.
- GPT-like 모델에 대해서 1.5B ~ 100B까지 6x 정도 throughput 향상을 가져왔다.
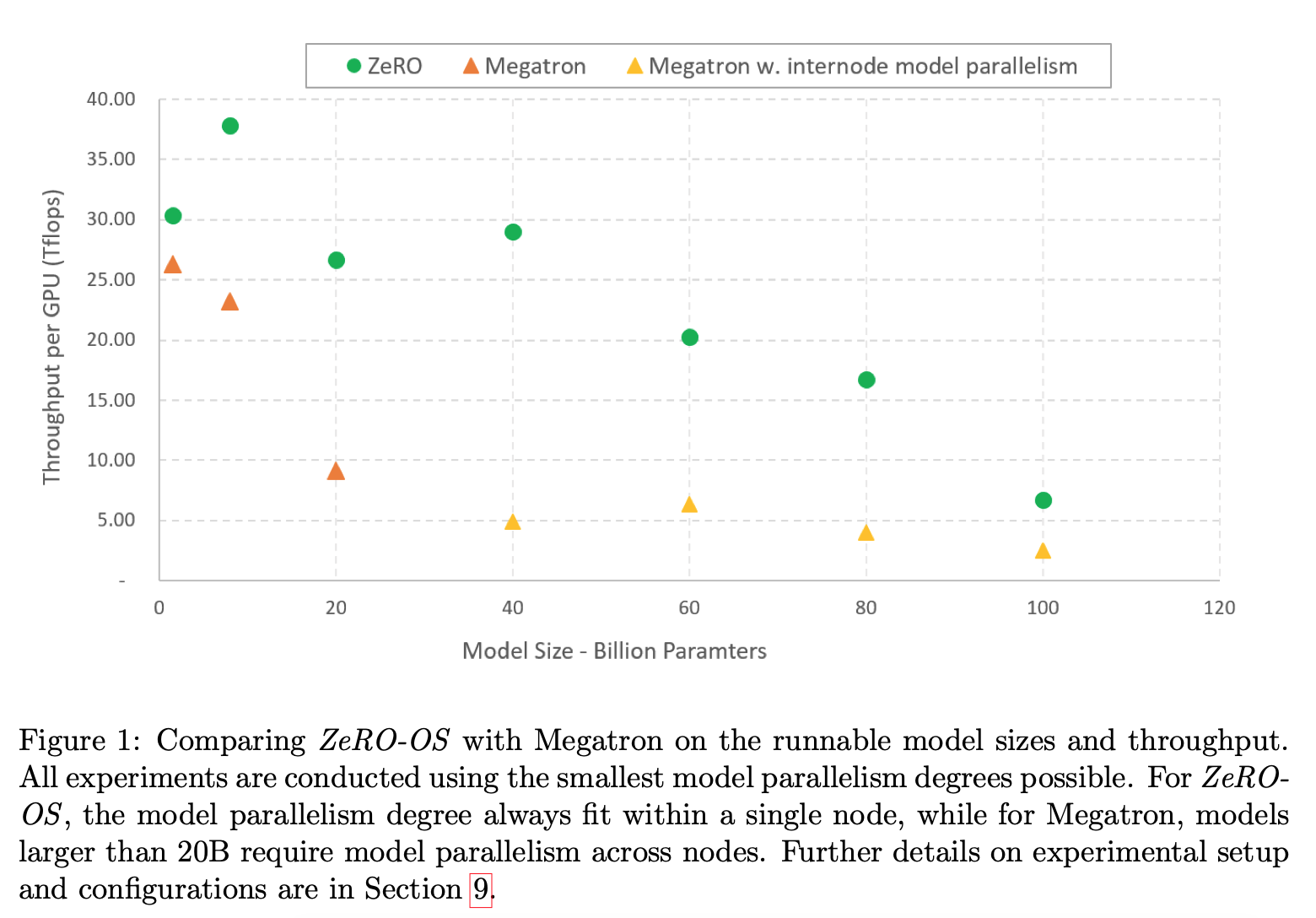
2 Background
진짜 Model Parallelism, Data Parallelism 설명이라 건너뜀
3 Where did all the memory go?
- 1.5B정도의 GPT-2 모델을 학습시키면 16-bit training때 3GB정도 weight만 저장한다. 근데 왜 32GB 메모리인 V100에서 학습하기가 어려울까?
- 대부분의 메모리를 사용하는 것
- Activations
- OGP States
- Temporary Buffers
- 뒤의 둘을 Optimize한다
3.1 Optimizer States, Gradients and Parameters
- Mixed Precision Training
- Parameter, Activation은 FP16으로 저장되고 high throughput을 보여준다.
- 하지만 backward propagation을 제대로 계산하기 위해서 fp32버전의 parameter와 optimizer states도 들고 있어야 한다.
- ADAM의 예시
- Moel Parameter 개수: \(\psi\)
- FP16 param: \(2\psi\) bytes, FP16 Gradients: \(2\psi\) bytes
- FP32 Copy, param: \(4\psi\) bytes, Momentum: \(4\psi\) bytes, Variance: \(4\psi\) bytes
- 총 \(16\psi\) bytes.
- GPT-2 (1.5B) 모델의 경우에 24GB의 메모리가 “최소한” 필요함
3.2 Temporary Buffers
- Gradient All Reduce, Graident Norm등에서 buffer가 필요함
- 전부 flatten되어서 주고 받아야하므로 \(4\psi\) bytes가 필요.
- GPT-2의 경우 6GB의 메모리가 필요함
4 ZeRO: Insights and Overview
- Efficiency는 아래 세개의 key insight에서 온다.
- Data parallelism은 scaling efficiency가 더 좋다. 그 이유는 model parallelism은 computing을 복잡하게 만들면서 communication overhead를 늘리기 때문
- Data parallelism은 model states를 전부 다 저장하기 때문에 memory inefficient하다. 그래도 Model Parallelism은 Memory Efficient하다.
- Model Parallelism과 Data parallelism은 Model States를 Training time동안 전부 저장한다. 하지만 계속해서 매 시간마다 필요한 것은 아니다.
- ZeRO는 그래서 OGP States를 replicating하는 대신 partition한다.
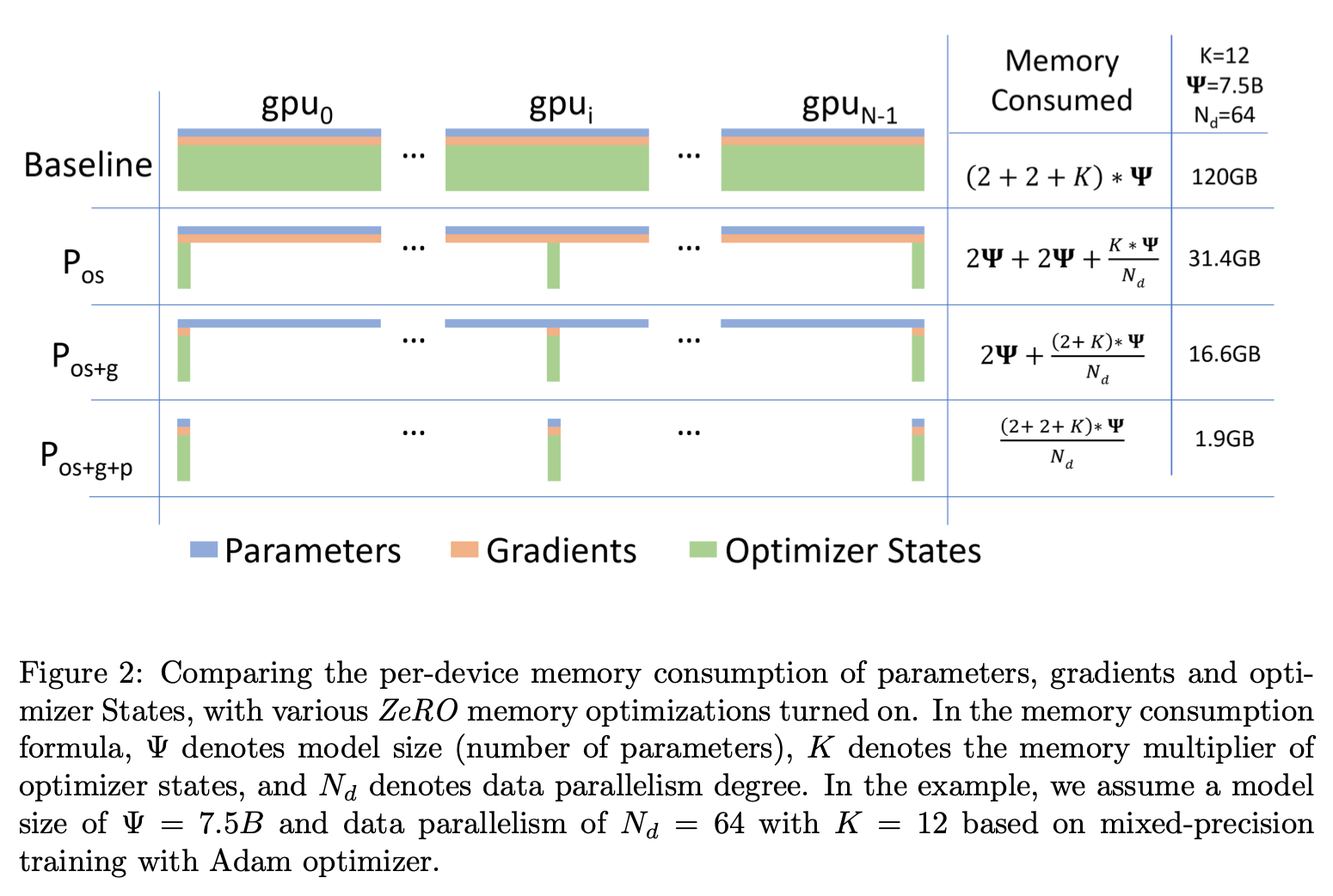
5 ZeRO: Memory Optimization
5.1 \(P_{os}\): Optimizer State Partitioning
- \(N_d\)의 Data parallelism degree라 할 때 optimizer states를 \(N_d\)로 똑같이 나눈다. 그리고 \(i_{th}\) data parallel process는 optimizer states를 해당 번호만 바꾼다. 그래서 optimizer states를 \(\frac 1 {N_d}\)만 들고 있으면 된다.
- all-gather를 하게 되면 전체 optimizer states가 나온다
- 큰 \(N_d\)에 대해서는 \(4\psi\)에 근사하는 memory reduction을 보여준다.
여기서 든 의문은 data parallelism degree라고 하는 것은 결국 data parallel process별로 다른 배치를 들고 있을텐데 그럼 optimizer states가 서로 달라지지 않나?라는 것이다. 서로 다른 데이터에 대해 다른 gradient가 잡히지 않을까?
5.2 \(P_g\): Gradient Partitioning
- Optimizer States를 나누어놓았으니 Gradients도 나누어 놓는 것이 좋다. (어차피 다른 건 들고 있어봤자..)
- 그래도 Backward는 똑같이 해야하니 Reduce Scatter를 bucketization strategy와 함께 사용한다.
- 아마 각 프로세스가 1 bucket인 것을 말하나 싶다.
5.3 \(P_p\): Parameter Partitioning
- Partition 밖의 Parameter는 forward, backward를 위해 필요하긴하다
- 그래도 그런 것들을 줄이기 위해 broadcast를 통해 적절한 data parallel process로부터 받아서 계산한다
- 이거보면 data parallel이어도 그냥 다 같이 계산하나?? 싶다
5.4 \(C_B\): Constant Buffer Size
- 모델이 너무 클때 constant-size fused uffer를 사용했다.
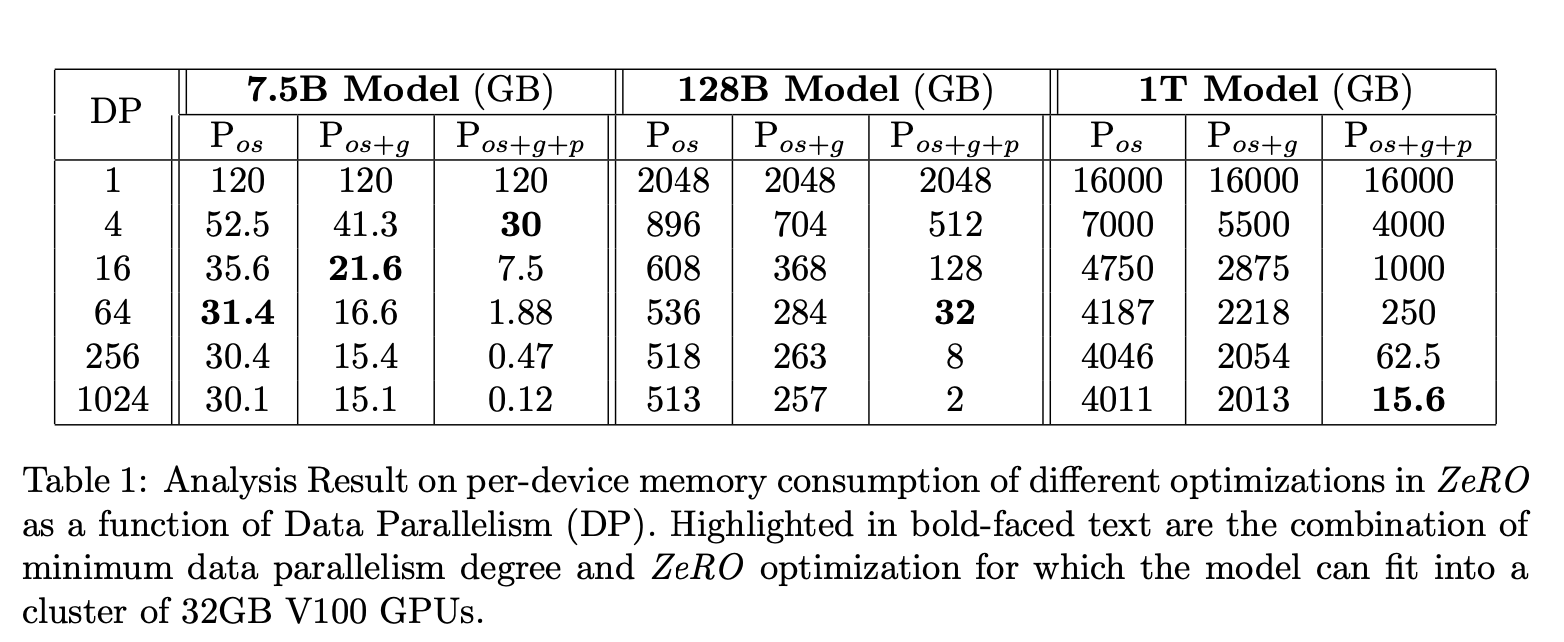
- 결국 \(N_d\)가 계속해서 커지면 8x까지 줄어든다
6 ZeRO: Communication Overhead
- All Reduce = Reduce Scatter + All Gather이므로 \(2\psi\) 만큼 데이터가 움직인다
- Communication Overhead of \(P_{os + g}\): Scatter Reduce (for Parameter update) + All Gather이므로 \(2\psi\) 만큼 데이터가 움직인다
- Communication Overhead of \(P_{os + g + p}\): forward propagation 때 parameter를 all gather로 주고받고 쓴 다음에는 버린다. 그 다음 backward 때는 역방향 \(1\psi\) -> 이거 잘 이해안감
- 총 \(3\psi\)의 Communication Overhead. 기존과 비교하면 1.5x만의 overhead
7 ZeRO & Model Parallelism
- ZeRO 쓰면 Model Parallelism은 조금 덜 필요함
- 그래도 도움이 될 수 있을지도 모른다. 하지만 너무 힘든 작업
–
이 뒤는 좀 핵심보다 구현 상세사항/실험이라 패스
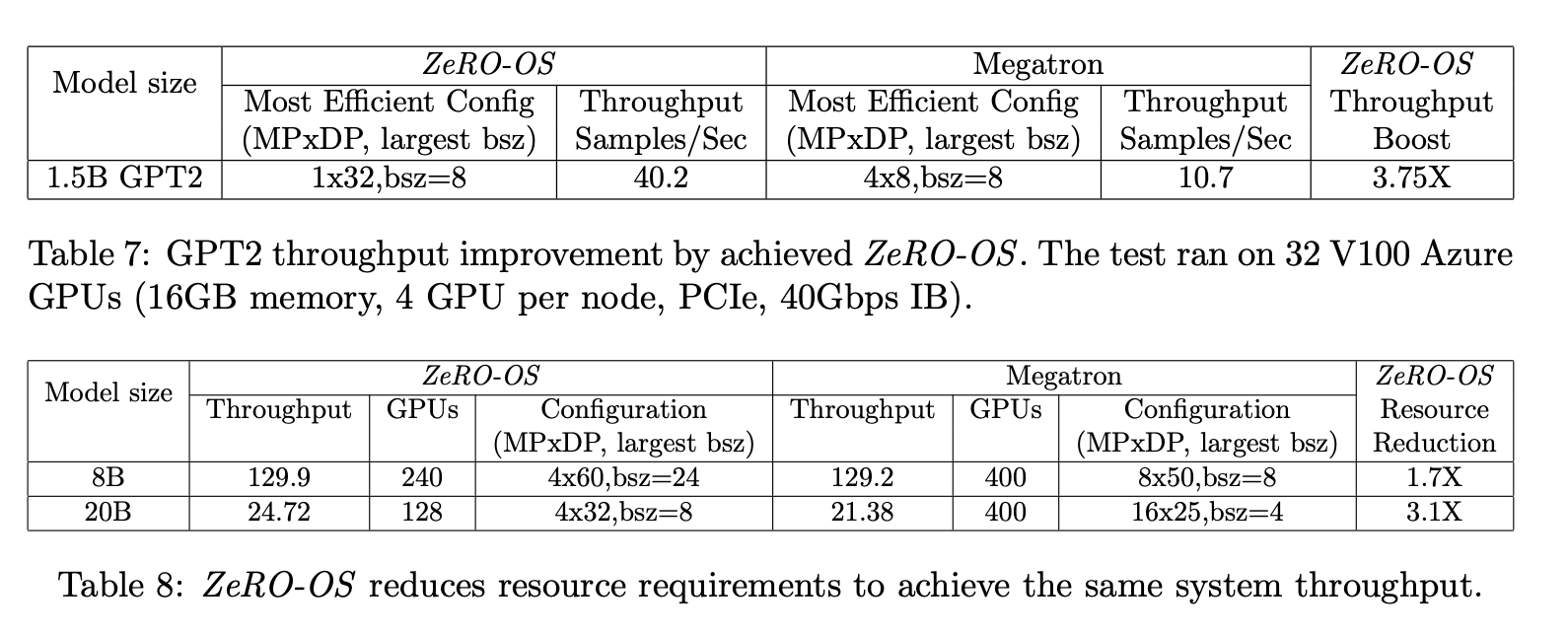
위는 제일 인상적인 결과
May 1, 2020
Tags:
paper